Sommario
Il transistor nato settantacinque anni fa ha contribuito a cambiare le attività umane come pochissime altre invenzioni nella storia. La sua realizzazione nei circuiti integrati ha segnato nel tempo una spettacolare riduzione delle dimensioni e del consumo di energia, con conseguente aumento del numero di transistor per chip e moltiplicazione delle applicazioni cui si rivolge. Seguiamo qui la sua storia e lo stato dell’arte oggi, indicando le prospettive di sviluppo per un prossimo futuro e i limiti fisici che a queste si imporranno.
Abstract
The transistor, born seventy-five years ago, has contributed to changing human activities like very few other inventions in history. Its implementation in integrated circuits has marked a spectacular reduction in size and energy consumption over time, with a consequent increase in the number of transistors per chip and an increasing variety of the applications where transistors are used. We follow the transistor history and the state of the art today, and indicate expectations for the near future and the physical limits that will be imposed on them.
Keywords
Semiconductor, MOSFET, FGMOS, Moore’s law, Integrated circuit
1. Introduzione
L’invenzione del transistor fu annunciata ufficialmente settantacinque anni fa e da allora più di ogni altra ha contribuito a incidere sulla vita dell’uomo consegnandogli importanti oggetti inimmaginabili prima e contribuendo a renderne più efficienti e fruibili innumerevoli altri. I transistor sono divenuti così piccoli e così numerosi all’interno di uno stesso supporto che, in un paese mediamente sviluppato, qualunque abitazione è invasa da miliardi di transistor senza che alcuno degli umani presenti se ne accorga: e se uno di essi va dal tabaccaio a comprare per pochi euro una chiavetta USB (tecnicamente, una flash memory) se ne mette in tasca qualche centinaio di miliardi. Naturalmente lo straordinario sviluppo dei transistor è stato graduale ma sempre più rapido, al punto che il contenuto del presente articolo, fatta salva la descrizione di quanto accaduto finora e il confronto tra qualche nostra previsione e la realtà futura, sarà completamente superato in brevissimo tempo.
Il nome, derivato dalla contrazione dei due termini “transconductance resistor”, indica un dispositivo atto a controllare il valore di una resistenza elettrica, ma forse ciò è ancora oggi ignoto a chi non si interessa di scienza o di tecnologia. Le persone non giovanissime come chi scrive (è un eufemismo) ricorderanno che negli anni ’60 del secolo scorso “il transistor” indicava invariabilmente la radiolina portatile a batteria che gracchiava ad alto volume nelle spiagge e nei giardini pubblici, in particolare la domenica nell’ora in cui si giocavano le partite di calcio. Oggi è correttamente di moda la parola chip, piccolo e in sostanza misterioso componente di circuiti elettronici che di transistor ne contiene moltissimi: moda innescata dalla pandemia di Covid 19 e non solo da essa, che ne ha causato una grave penuria rendendo a sua volta introvabili in breve tempo tanti dispositivi che li includono per il loro funzionamento, dalle automobili alle lavastoviglie per non dire ovviamente dei computer.
Seguiamo dunque la storia dei transistor dalle origini ai giorni nostri parlando dei principi fisici su cui sono basati e del loro sviluppo negli anni; dell’integrazione nei chip e dei metodi di fabbricazione; dei problemi legati alla velocità di funzionamento e consumo di energia; dello sviluppo dell’industria che li riguarda; dei limiti fisici sulla loro miniaturizzazione che condizionerà l’evoluzione dei chip.
Dalla punta di contatto al FinFET

Figura 1
Gli inventori del transistor
Nella famosa immagine di figura 1, rilasciata dalla AT&T ai tempi dell’invenzione del transistor, appaiono i tre scienziati cui nel 1956 fu attribuito il premio Nobel per la fisica “per le loro ricerche sui semiconduttori e la loro scoperta1 dell’effetto transistor”. Sono da sinistra John Bardeen, Walter Brattain e William Shockley che lavoravano che lavoravano presso i Bell Labs della AT&T ai tempi della scoperta1. Tre caratteri molto diversi tra cui si crearono spiacevoli dissapori dopo il 16 Dicembre 1947 quando il primo transistor della storia prese a funzionare tra le mani di Bardeen e Brattain che ne fecero una richiesta di brevetto. L’invenzione fu resa pubblica in una conferenza stampa presso i Bell Labs nel Giugno 1948: si trattava del point-contact transistor (transistor a punta di contatto). Shockley, che era il capo del gruppo in cui si svolgevano quelle ricerche e aveva preso malissimo l’assenza del suo nome dalla richiesta originale di brevetto continuò da solo i suoi studi e nel Dicembre del 1948 completò il progetto del nuovo bipolar junction transistor (BJT, transistor bipolare o a giunzione) che avrebbe dominato il campo fino agli anni ’70 ed è tuttora, dopo una naturale evoluzione nel tempo, alla base dei circuiti analogici. Due dispositivi diversi dai field effect transistor (FET, transistor a effetto di campo) di cui anche parleremo, che dominano oggi l’elettronica digitale.
Accenneremo solo alle proprietà e al funzionamento dei transistor che molti lettori conosceranno già, ma vogliamo ricordare anzitutto alcune caratteristiche dei materiali impiegati per comprendere i limiti fisici che la tecnologia comincia ad affrontare oggi. I transistor sono costruiti su materiali semiconduttori che hanno una conduttività elettrica intermedia tra quelle dei conduttori e degli isolanti. Ricordiamo che i valori di questo parametro sono distantissimi tra conduttori, semiconduttori e isolanti, e quello dei semiconduttori in forma di cristallo varia fortemente in funzione di elementi chimici in essi presenti. In particolare consideriamo il silicio cristallino che oggi domina le applicazioni e il germanio su cui furono costruiti i primi transistor.
L’atomo di silicio ha quattro elettroni di valenza. Il cristallo, come quello del diamante, è cubico a facce centrate: ogni atomo si trova al centro di un tetraedro i cui vertici ospitano ciascuno un altro atomo di silicio (Si) con cui il primo scambia un legame covalente attraverso i suoi quattro elettroni di valenza. Questa struttura estremamente regolare può essere “drogata” con atomi di elementi prossimi nella tavola periodica: per il silicio i droganti sono il fosforo (P) e il boro (B) che di elettroni di valenza ne hanno rispettivamente cinque e tre. Per ottenere il drogaggio, atomi ionizzati di fosforo o boro sono spinti da un campo elettrico sulla superficie del cristallo e lo penetrano a profondità controllata sostituendo atomi di silicio nella struttura cristallina.
In un modello idealizzato del fenomeno, sostituendo un atomo di Si con P, l’elettrone di valenza di P che non trova posto nel legame chimico è libero di spostarsi nel cristallo: se questo è soggetto a un campo elettrico esterno l’elettrone contribuisce a una corrente elettrica complessiva la cui intensità dipende dall’entità del drogaggio. Il materiale così ottenuto si chiama silicio-n ove
n sta per negativo. Similmente sostituendo un atomo Si con B l’elettrone di valenza mancante in B genera una lacuna, e questa può essere invasa da un elettrone di un legame vicino tra altri due atomi Si lasciando una lacuna tra questi: il fenomeno ripetuto a catena è descritto come flusso di lacune anche se di fatto è un flusso di elettroni in senso inverso, e contribuisce anch’esso a una corrente elettrica se il cristallo è soggetto a un campo elettrico esterno. Il materiale così ottenuto si chiama silicio-p ove p sta per positivo: ecco dunque realizzati due semiconduttori con proprietà in certo senso opposte. Il materiale di base dei primi transistor era il germanio (Ge), impiegato dall’inizio del 1900 a oggi per la costruzione di diodi. Gli elementi di drogaggio che danno luogo a germanio-n e germanio-p possono essere l’arsenico (As) e il gallio (Ga).
Il motivo per cui ricordiamo questi aspetti del drogaggio, probabilmente noti a tutti i lettori, è per meglio spiegare i limiti fisici che la tecnologia dei transistor inizia a incontrare oggi. Anzitutto un cristallo di silicio contiene in ordine di grandezza 1022 atomi/cm3. Ciò significa che il raggio di Van der Vaals, ossia il raggio di una sfera ideale occupata da un atomo del cristallo, è di 210 pm = 0.21 nm (ricordiamo che p = 10-12 e n = 10-9: come vedremo le dimensioni dei transistor di oggi si avvicinano a questi valori e quelli che si chiamavano micro-circuiti sono ormai nano-circuiti). Un cristallo idealmente puro ha conduttività elettrica bassissima ed è praticamente isolante, ma cristalli puri non è possibile ottenerli artificialmente: in quelli utilizzati oggi le impurità inevitabili sono dell’ordine di 109 atomi/cm3, quantità sufficientemente bassa per considerarli isolanti per i livelli di segnale impiegati. L’entità media del drogaggio indotto artificialmente è invece dell’ordine di 1015 atomi/cm3, quindi silicio-p e silicio-n sono conduttori, anche se non buoni.
Una struttura di base per la costruzione del transistor è la giunzione, cioè la superficie di contiguità tra un cristallo di silicio-p e uno di silicio-n, nei fatti la contiguità tra due zone drogate p e n dello stesso cristallo. Le due zone, elettricamente neutre, si caricano rispettivamente in modo negativo e positivo presso la giunzione a causa di una diffusione di elettroni dalla zona n alla zona p e di lacune in senso inverso. Questo fenomeno crea attorno alla giunzione una differenza di potenziale (barriera) tra le due zone, negativa in p e positiva in n, che si stabilizza a un valore di soglia di circa 0.6 Volt per il silicio di 0.3 Volt per il germanio, e contrasta l’ulteriore diffusione di cariche. Una struttura così formata ha comportamento di un diodo anche se non ideale perché inizia a condurre per una tensione esterna di polarità concorde alla barriera e di valore superiore alla soglia, e non conduce per una tensione esterna inversa (non troppo elevata perché distruggerebbe il dispositivo).
La giunzione, caratteristica essenziale dei diodi a semiconduttore, è presente in tutti i transistor a cominciare dal primo a punta di contatto. Questo, come tutti gli altri, è connesso all’esterno con i tre terminali emettitore-base-collettore (successivamente chiamati source-gate-drain), anche se l’impiego di essi differisce tra i vari tipi di transistor. Parliamo anzitutto brevemente del primo che ha un interesse unicamente storico e ha un funzionamento piuttosto complicato che probabilmente all’inizio non fu interamente compreso neanche dagli inventori. Il transistor a punta di contatto mostrato schematicamente nella figura 2 è costituito da una piastrina di germanio la cui parte inferiore drogata p è connessa a un conduttore metallico a terra che costituisce la base, e sulla parte superiore drogata n poggiano, vicinissime tra loro, le punte di due lamine d’oro come emettitore e collettore (l’impiego dell’oro, materiale non ossidabile, è comune anche oggi perché assicura la costanza di buoni contatti nel tempo). Tra le zone n e p si stabilisce una giunzione che consente un passaggio di corrente tra emettitore e base se il primo è polarizzato positivamente superando la barriera, ma che in linea di principio blocca una corrente in senso inverso tra collettore e base. Tuttavia le lacune iniettate nella zona p dall’emettitore sono attratte in gran numero dalla tensione negativa del vicinissimo collettore tendendo ad abbattere localmente la barriera. L’effetto complessivo è quello che, per opportuni valori delle tensioni in gioco, la corrente emettitore-base causa una corrente collettore-base in senso opposto modulata dai valori della prima, le cui variazioni possono essere molto più intense di quelle del circuito dell’emettitore. Era così realizzato il sogno inseguito da molti a quel tempo di ottenere l’amplificazione di un segnale impiegando un semiconduttore anziché un tubo a vuoto come il triodo.
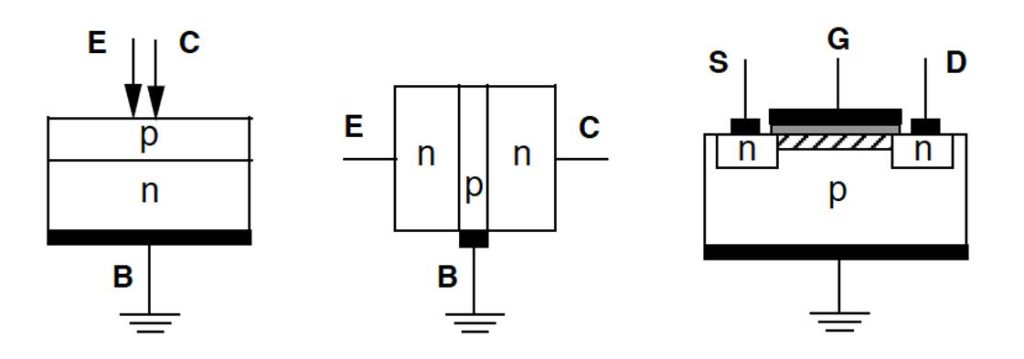
Figura 2
Schizzo dei transistor. Da sinistra: a punta di contatto, bipolare, nMOS. E, B, C indicano Emettitore, Base, Collettore. S, G, D indicano Source, Gate, Drain. Le zone nere sono contatti metallici, la zona grigia è ossido SiO2 isolante, la zona tratteggiata è il canale.
Il transistor a punta di contatto ha il merito indiscutibile di essere sato il primo a funzionare e fu prodotto fino al 1966 dando origine al declino dei tubi a vuoto; ma il transistor bipolare (BJT) nato subito dopo e entrato in commercio all’inizio degli anni ’60 era destinato a un successo molto superiore per i livelli di potenza con cui poteva operare e per una struttura sostanzialmente meno fragile perché evita il contatto critico tra il semiconduttore e le punte, tanto da essere prodotto fino a oggi dopo una logica evoluzione nel tempo. Nel transistor bipolare mostrato schematicamente nella figura 2 il semiconduttore, prima germanio e oggi quasi esclusivamente silicio, è diviso in tre zone consecutive drogate p-n-p on-p-n, con le due estreme collegate a emettitore e collettore e quella centrale,molto più sottile e meno drogata delle altre, collegata alla base: al suo interno visono dunque due giunzioni come in tutti i transistor che l’avrebbero seguito e, aquanto possiamo prevedere, come avverrà ancora nel prossimo futuro. Una
corrente locale tra base e emettitore ne controlla una assai più intensa tra collettore e emettitore. Per spiegarne a grandi linee il funzionamento consideriamo il tipo n-p-n.
Una tensione di controllo negativa applicata all’emettitore attrae elettroni nella sottile zona p attraverso un corrente tra base ed emettitore combinandosi con le poche lacune della zona e liberando il passaggio di elettroni nell’intero corpo del transistor. Questi sono attratti in gran numero da una tensione positiva tra collettore ed emettitore assai superiore di quella tra base ed emettitore. La modulazione della corrente base-emettitore controlla e amplifica quella collettore-emettitore.
I transistor a punta di contatto e bipolari sono particolarmente adatti all’impiego in circuiti analogici, ma la possibilità puramente binaria di permettere o vietare la circolazione di una corrente in un circuito ne consentiva ovviamente l’impiego nei sistemi digitali. Molto più adatto per questi ultimi sono i transistor di tipo MOS, o più propriamente MOSFET per metal-oxide-semiconductor field-effect-transistor o transistor a effetto di campo. Inventato anch’esso nei Bell Labs nel 1959, il MOS fu posto in commercio qualche anno più tardi e, in versioni via via più evolute, ha guadagnato rapidamente una completa supremazia nelle applicazioni digitali ove anche oggi è il più largamente impiegato. È anch’esso di norma composto di silicio con tre zone drogate p-n-p (detto pMOS) o n-p-n (detto nMOS): contiene quindi due giunzioni e ha tre terminali che prendono ora il nome di source, gate e drain (S, G, D), ma diversamente dai precedenti la corrente tra source e drain è regolata da una tensione sul gate; un quarto terminale connette a terra il semiconduttore. Anche di questo diamo una descrizione schematica con riferimento alla figura 2 per un transistor nMOS.
Il principio di funzionamento è semplice. Come si vede la placca del gate e il corpo del semiconduttore a cui è opposta, separate da un sottile strato isolante, costituiscono di fatto un condensatore, ed è sulla carica e scarica di questo che si basa il comportamento del dispositivo. Se G è a tensione di terra (condensatore scarico) la presenza di due giunzioni opposte n-p e p-n impedisce il passaggio di corrente tra S e D. Se G è a tensione positiva rispetto a terra e superiore alla barriera delle giunzioni (condensatore carico), questa respinge le lacune della zona p e attira elettroni dalle zone n, che convergono in un sottile strato di semiconduttore adiacente all’isolante detto canale: per un opportuno valore di tensione di G questi elettroni sono sufficienti a costituire un percorso continuo con gli elettroni liberi delle due zone n del transistor, e S e D sono messi in contatto. In sostanza la tensione su G rende isolante o conduttore il percorso S – D: una situazione interpretabile in modo puramente binario nei circuiti digitali.
Il funzionamento di un transistor pMOS è in certo senso opposto. Un’opportuna tensione negativa su G attira lacune nel canale ponendo in contatto S con D, mentre la tensione di terra su G blocca la conduzione.
Il dispositivo immediatamente costruibile attorno al transistor nMOS (o similmente pMOS) è l’invertitore schematizzato nella figura 3, che realizza l’operazione logica di NOT tra l’ingresso I su G e l’uscita U su S. Rappresentando i valori 0 – 1 di un bit come due tensioni V0 – V1 (tipicamente tensione di terra per
V0 e positiva di qualche decimo di Volt per V1) l’operazione NOT implica che per I = 0 (cioè G = V0) sia U=1 (ciè S= V1) e viceversa. A tale scopo si collegano S a V1 attraverso un resistore R, e D a V0. Ponendo G = V0 il transistor non conduce, il circuito S – D è aperto e si ha S = V1 poiché non vi è corrente nel circuito e quindi caduta di tensione su R. Ponendo G = V1 il circuito S – D è chiuso e S è praticamente collegato a terra perché la resistenza del canale è trascurabile rispetto a R: si ha quindi S = V0.
Come spieghiamo sotto questo non è esattamente il circuito impiegato oggi, ma la semplice realizzazione del NOT ha una conseguenza importantissima:
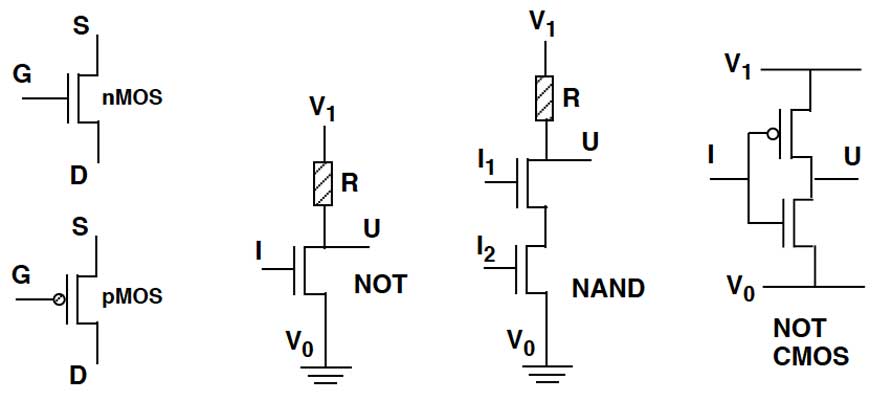
Figura 3
Da sinistra. Simboli dei tansistor MOS. Il circuito invertitore. Un NAND a due ingressi. Il circuito invertitore CMOS
ponendo due (o più) transistor in serie si realizza l’operazione logica di NAND il cui valore è 0 se e solo se tutte le variabili d’ingresso hanno valore 1. Nel circuito, anch’esso indicato nella figura 3, l’uscita U è rilevata sul contatto S del primo transistor e gli ingressi I1, I2 per ogni variabile sono applicati ai gate G dei differenti transistor: è sufficiente che il gate G di uno dei transistor della catena sia interrotto (G = V0) perché non transisti corrente e si abbia S = V1; se tutti i G sono a V1 la catena conduce e si ha S = V0. Se i transistor sono invece posti in parallelo si realizza l’operazione NOR il cui valore è 1 se e solo se tutte le variabili d’ingresso hanno valore 0. Come è noto dalla teoria della commutazione il solo operatore NAND o NOR è sufficiente per esprimere qualunque funzione booleana e quindi costruire qualunque rete di calcolo2. Inoltre collegando tra loro ad anello due transistor si realizza un flip-flop, cioè un circuito stabile in due condizioni (se un transistor conduce l’altro è bloccato, e viceversa) che consente di memorizzare un bit. Collegando transistor si può quindi realizzare un intero microprocessore, il circuito più avanzato ospitato da un chip.
La presenza del resistore R nel circuito invertitore o NAND sopra descritto causa ovviamente un consumo di energia quando i transistor sono in conduzione.
Questo problema, che è divenuto sempre più grave con la moltiplicazione del numero di transistor, si rivelò serio sin dall’inizio anche per la dissimmetria di consumo tra un’operazione e la sua inversa. La soluzione denominata CMOS (C indica complementary), ideata nel 1963 da Frank Wanlass e Chi-Tang Sah e commercializzata dalla RSA a partire dal 1968, è ormai adottata come standard. L’invertitore CMOS, anch’esso indicato nella figura 3, è composto da due transistor connessi in serie: un nMOS detto pull-down e un pMOS detto pull-up. L’ingresso I è applicato a entrambi i gate. L’uno o l’altro transistor conduce se la tensione sul gate è rispettivamente maggiore (G = V1) o minore (G = V0) della tensione di soglia connettendo l’uscita U rispettivamente a V0 o V1 senza l’impiego di resistori3.
L’evoluzione dei transistor CMOS che avrebbe condotto alla struttura impiegata oggi fu imposta principalmente da problemi elettrici che si stabiliscono all’interno del dispositivo con la riduzione delle dimensioni minime (tecnicamente detta feature) di ogni sua parte. Con feature di 350 nm raggiunta nel mezzo degli anni ’90 cominciarono a manifestarsi fenomeni non immediatamente spiegabili con l’elettrotecnica classica, soprattutto correnti parassite che superavano gli strati isolanti; queste causavano dissipazione di energia e un imprevisto invecchiamento dei materiali con conseguente degradazione delle prestazioni. La persona chiave in questa evoluzione fu Chenming Hu, professore dell’Università di California a Berkeley e inventore del transistor detto FinFET (fin, cioè pinna) che oggi domina le applicazioni.
Come si intuisce dalla figura 2 il transistor MOS è costituito da strati sovrapposti ed è detto planare, in contrapposizione al FinFET di figura 4 che si sviluppa in tre dimensioni con le zone di S-D e G poste verticalmente. La “pinna” si riferisce al sottilissimo strato di silicio drogato che contiene il canale, contornato dal gate da entrambe le parti con maggiore efficienza di funzionamento rispetto
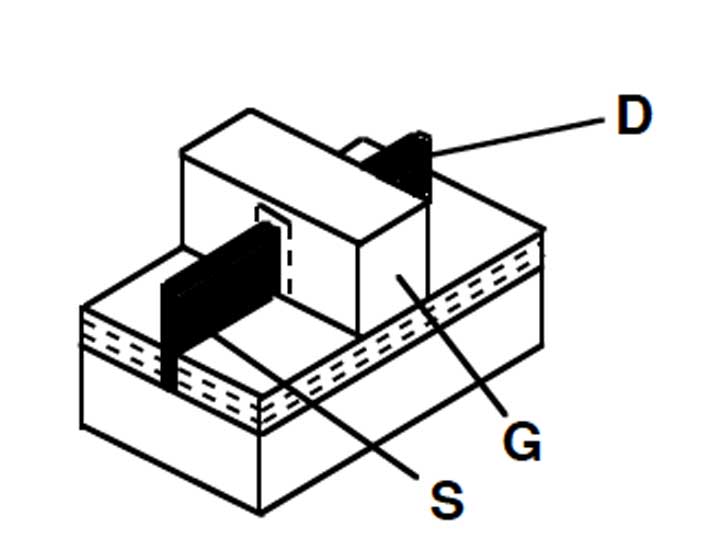
Figura 4
Il transistor FinFET. La zona a puntini è isolante, la pinna è in nero.
al MOS planare e perdite parassite molto inferiori. Il progetto con i primi prototipi fu presentato da Hu nel 2000, fu a lungo discusso per la difficoltà di realizzazione e fu posto in commercio per la prima volta dalla Intel nel 2011 con una feature ormai ridotta a 25 nm. Oggi in diverse versioni è lo standard: le tensioni, i consumi e il tempo di commutazione si sono drasticamente ridotti e la produzione di FinFET ha dato inizio a un possibile sviluppo di chip in tre dimensioni di cui parleremo in seguito.
Vogliamo infine parlare di un altro tipo di transistor oggi molto diffuso, che mostra come la tecnologia abbia raggiunto limiti consentiti solo dallo studio della meccanica quantistica. Ci riferiamo ai floating-gate MOS (FGMOS) che costituiscono tra l’altro le memorie flash, economicissimo mezzo di memorizzazione di dati. Precedute da altri dispositivi basati su simili principi, le memorie flash costruite oggi sono nate dagli studi compiuti negli anni ’80 nei laboratori Toshiba da Fujio Masuoka, e sono divenute di largo impiego una decina d’anni più tardi.
Nel FGMOS ogni cella contiene un ulteriore floating gate FG completamente isolato dal resto, posto all’interno dell’isolante tra gate G e canale e separato da questo da un sottilissimo strato di ossido. Una (alta) tensione di alcuni volt applicata a G causa un intenso flusso di elettroni nel canale, alcuni dei quali superano il sottile strato isolante trasferendosi in FG dove possono rimanere per molto tempo: questa migrazione avviene secondo diversi fenomeni quantistici a seconda del tipo di transistor, ed è interpretata come la memorizzazione di un bit 0 mentre l’assenza di carica in FG rappresenta il bit 1. Gli elettroni eventualmente presenti in FG modificano la tensione di soglia del transistor che ora reagisce alla tensione applicata su G commutando o meno a seconda del valore di tale soglia: la corrispondente presenza o assenza di corrente tra S e D è utilizzata come lettura del bit memorizzato.
Le memorie flash furono impiegate inizialmente per memorizzare dati che non richiedevano accessi troppo frequenti che avrebbero potuto danneggiarle. Oggi hanno raggiunto un tale livello di qualità da essere utilizzabili anche nei personal computer ove sostituiscono i dischi consentendo ridottissimi tempi di accesso rispetto a questi.
I circuiti integrati e la legge di Moore
Dieci anni dopo la nascita del transistor cominciò a farsi strada l’idea che i semiconduttori avrebbero acquisito un ruolo fondamentale nel mercato se fosse stato possibile costruire su essi interi circuiti contenenti componenti passivi e transistor, riducendone le dimensioni fino a miniaturizzarli. Come racconta un bell’articolo di Silvio Hénin uscito su questa rivista [2] due proposte di brevetto furono depositate nel 1959 da Jack Kilby della Texas Instruments e successivamente da Robert Noyce della Fairchild sulla realizzazione di circuiti integrati (IC), nome derivato dalla stessa proposta di Kilby circa “un nuovo circuito elettronico miniaturizzato fabbricato su un corpo semiconduttore in cui tutti i componenti del circuito sono completamente integrati” (comunemente si usa oggi
il termine chip anche se questo dovrebbe riferirsi alla sola piastrina su cui è realizzato). Ne seguì una lunga competizione legale sulla priorità della proposta ma nel 1966 le due società si accordarono per mettere in comune i due brevetti e iniziò lo sviluppo inarrestabile di questa tecnologia. Un momento simbolico fu la nascita dello Intel 4004, primo processor completamente integrato su un chip con il contributo essenziale dell’italiano Federico Faggin.
Un anno prima dell’accordo tra Texas Instruments e Fairchild, Gordon Moore cofondatore della Fairchild pubblicava un breve articolo su una rivista sul commercio elettronico. Spiegato il ruolo preminente che avrebbero assunto in diversi campi i circuiti elettronici, esprimeva una previsione sul loro sviluppo nei circuiti integrati che avrebbe acquisito nel tempo una grande popolarità sotto il nome di Legge di Moore [3]4.Le sue parole, che citiamo testualmente, affermavano che i circuiti elettronici “will be regulated by a yearly doubling in the number of components that can be economically packed in an integrated circuit”. Accompagnavano la figura 5, tratta dal suo articolo, che indica la curva del costo per componente in funzione del numero di componenti come rilevata nel 1962 e 1965 e prevista per il 1970, simile per tutti i metodi di produzione allora sperimentati.
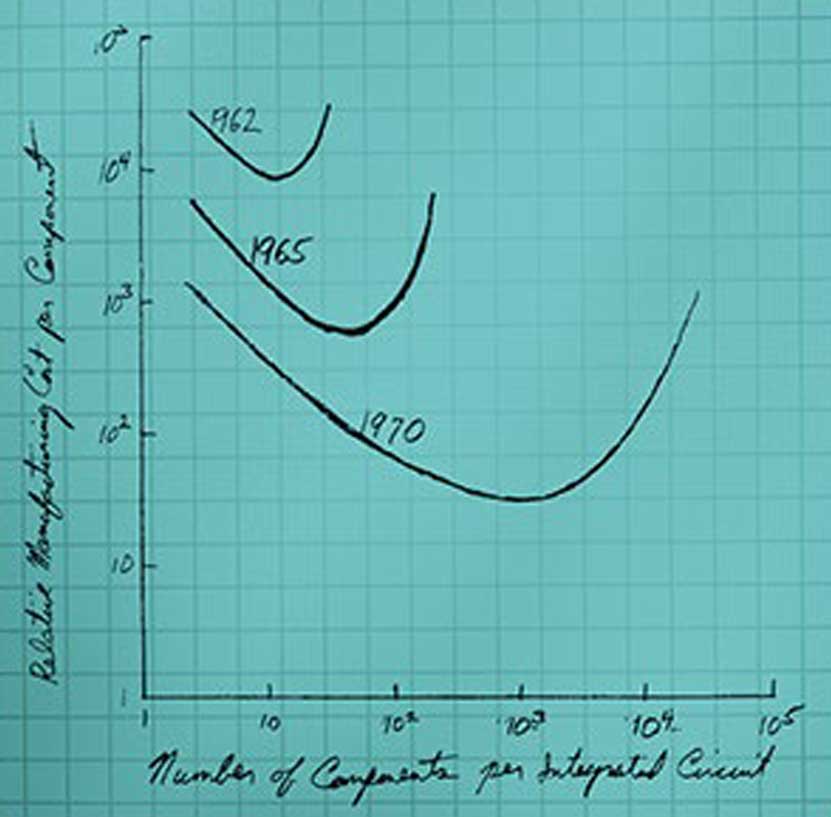
Figura 5
La legge di Moore, nell’immagine tratta dal suo articolo [3].
Abbiamo sottolineato noi la parola “economically” perché su questo punto era concentrata l’affermazione: il famoso raddoppiamento annuale del numero di componenti nel chip con cui la legge viene espressa popolarmente è molto
riduttivo rispetto al concetto espresso da Moore. Ogni tecnologia costruttiva ha una curva di costo che fino a un certo punto diminuisce se si impaccano più componenti in un circuito integrato, ma oltre un certo valore il costo per componente cresce perché il yield di produzione, cioè il numero di esemplari funzionanti, diminuisce. La curva con il suo punto di minimo costo per componente si muoverà nel tempo permettendo di aumentare sempre più il livello di integrazione dei circuiti.
La legge di Moore, anche nella sua accezione semplificata, ha continuato a valere per anni con un’ovvia rimodulazione del tempo necessario al raddoppio dei componenti. Sostanzialmente la natura esponenziale della crescita è stata rispettata fino al 2018, anno in cui sembrava arrestarsi per la difficoltà di spingere la miniaturizzazione oltre certi livelli. L’entrata in funzione di apparati innovativi l’ha rimessa in marcia fino al limite odierno, ma da ora solo un drastico cambiamento nella struttura dei chip potrà conservarla. Per parlare di tutto questo occorre prima descriverne brevemente la tecnologia costruttiva dei chip.
Evoluzione della produzione: problemi emersi e proiezione nel futuro
La produzione di circuiti integrati è ovviamente molto complessa e ha raggiunto uno stato di altissima perfezione tecnologica con il diminuire delle dimensioni dei componenti (feature, come già detto). L’elemento di base è un disco (wafer) tagliato da una barra cilindrica di silicio cristallino, su cui vengono costruiti tanti chip tutti uguali che saranno divisi tra loro a fine procedimento. I wafer hanno oggi uno spessore di circa 0.5 mm e un diametro fino a 30 cm. La costruzione di un chip passa attraverso la realizzazione di strati successivi di drogaggio e deposizione di materiali sulla superficie secondo forme comandate da una serie di maschere, cioè disegni ridotti in scala microscopica e sovrapposti al chip per definire le zone da modificare su ogni strato. Ogni maschera è ripetuta in tante copie adiacenti per generare tanti chip uguali su ogni wafer.
Accenniamo solo che una maschera ha zone opache o trasparenti. La superficie del semiconduttore, inizialmente scaldata per ricoprirla di ossido isolante, è cosparsa di resina, la maschera viene a questa sovrapposta e una radiazione attraversa le zone trasparenti causando la polimerizzazione locale della resina che si solidifica in quelle zone e le protegge da successivi attacchi. Tolta la maschera si asporta chimicamente la resina non polimerizzata e se necessario anche l’ossido sottostante lasciando esposte le zone che richiedono un trattamento in quello strato del chip come drogaggio o deposizione di materiali conduttori. Si procede così strato per strato isolandoli tra loro e realizzando le connessioni tra strati consecutivi attraverso vias, cioè fori nell’isolante riempiti di tungsteno. Le zone drogate sono nei primi strati e quelli superiori contengono le connessioni metalliche che tipicamente possono invadere fino a venti strati.
Questo procedimento detto fotolitografico, realizzato all’inizio con la luce visibile, si era trasferito col tempo nel campo degli ultravioletti: una transizione indispensabile per la riduzione della feature perché con una radiazione luminosa
non si possono definire dettagli inferiori alla sua lunghezza d’onda. Nel 2018, anno chiave per questa discussione, la minima lunghezza d’onda impiegata era di 193 nm e la feature dei chip più avanzati era attorno ai 10 nm. Questa apparente contraddizione era dovuta a un procedimento lungo e costoso detto multiple patterning consistente nel definire le forme su uno strato del cip attraverso successivi passaggi con maschere diverse spostate un rispetto all’altra di pochi nanometri. Il procedimento non poteva comunque essere ripetuto per troppe passate per motivi di costo e di precisione, ed era chiaro da almeno vent’anni che per ottenere feature più piccole si sarebbe dovuto ricorrere all’impiego di radiazioni di lunghezza d’onda decisamente inferiore. Le principali compagnie di produzione erano impegnate in questo affrontando gravi difficoltà tecnologiche, in particolare l’impossibilità di ridurre e concentrare le immagini delle maschere sul wafer mediante lenti perché, al crescere della frequenza, l’intera energia della radiazione sarebbe stata assorbita da esse. Nel 2018 la ASML, una società olandese che aveva perfezionato per anni il progetto, mise per prima in commercio un’apparecchiatura che impiegava radiazione EUV (Extreme Ultra Violet) a 13.5 nm in grado di produrre chip a 7 nm. In particolare la concentrazione della radiazione era ottenuta con un sistema di specchi speciali in cascata prodotto dalla Zeiss: in questo modo ben il 2% dell’energia prodotta raggiungeva il chip! È doveroso aggiungere che l’apparato della ASML assorbiva circa 1.5 MW di potenza e come in tutte le catene di produzione dei chip doveva essere tenuto in funzione giorno e notte senza interruzione.
Il 2018 segna l’inizio di una nuova era. La tecnologia di oggi impiega radiazione EUV e raggiunge una feature minima di 4 nm, sono già in cantiere produzioni a 3 nm e vi sono nuove fabbriche in allestimento che l’anno prossimo inizieranno la produzione a 2 nm. Come detto il raggio di Van der Vaals nel cristallo di silicio è 0.21 nm: la pinna del FinFET conterrà trasversalmente solo qualche atomo, posto che questa affermazione abbia un corretto senso fisico5. Ma apparentemente i progressi non si fermeranno qui.
La prima considerazione da fare a questo riguardo è che lo sviluppo dei chip è legato a problemi di progettazione in parte indipendenti dalle tecnologie di produzione. Il più importante è quello del consumo di energia a cui si lega il riscaldamento del circuito che può comprometterne il funzionamento, principalmente dovuto alle connessioni elettriche che come già detto sono ospitate negli strati superiori. Naturalmente al crescere del numero di transistor cresce il numero di connessioni che nelle tecnologie più spinte hanno una lunghezza complessiva valutabile in molte decine di km per cm2. Queste connessioni sono realizzate in alluminio più facile da depositare, ma al diminuire della feature l’alluminio è sostituito in genere dal rame che ha una conduttività maggiore e produce meno dispersione termica: e qui stanno nascendo problemi inaspettati a un non esperto.
Un conduttore di rame è soggetto al fenomeno quantistico della elettromigrazione sconosciuto all’elettrotecnica classica, secondo il quale gli elettroni che lo percorrono possono dislocare per urto atomi del metallo, spinti nell’isolante esterno a esso: correnti intense possono causare l’interruzione della conduzione in conduttori molto sottili che sono quindi protetti con “bordature” di altri materiali aumentandone però l’ingombro. Per questo scopo si sta sperimentando il grafene che può essere depositato in strati estremamente sottili attorno al rame, ma è ormai riconosciuto che per diminuire lo spessore dei collegamenti il rame dovrà essere sostituito: da tungsteno o cobalto per quanto indicato oggi, ma il cambiamento comporterà un complesso cambiamento del procedimento di produzione dei chip e per ora le realizzazioni si limitano a prototipi.
Un altro fenomeno tipicamente ingegneristico che forse stupirà i “non addetti ai lavori” interessa il progetto complessivo dei chip: se ne parla ormai da qualche anno in tutti i convegni e riunioni specializzate ma finora quasi nulla è stato fatto. Nelle operazioni di un chip, in particolare se contiene un intero microprocessore, l’energia e il tempo necessari per trasferire i dati dalla memoria ai circuiti di calcolo (di fatto ai transistor) sono molto superiori all’energia e al tempo richiesti da questi ultimi per eseguire un’operazione su di essi. I dati pubblicati in [4], relativi a un microprocessore di riferimento, indicano che spostare di 1 mm in parallelo due parole di 32 bit richiede 1.9 pJ e 400 ps mentre un’addizione tra di esse richiede 20 fJ e 150 ps (ricordiamo che p (pico) indica 10-12 e f (femto) indica 10-15). In particolare l’enorme differenza tra i due valori dell’energia è dovuta all’effetto Joule nei conduttori. La soluzione, prospettata da tutti e per ora sperimentata in modo parziale principalmente dalla Samsung, viene indicata come in-memory computing e consiste nell’avvicinare tra loro sul chip memoria e CPU, operazione che richiede alcune trasformazioni nella tecnica di produzione.
Per quanto riguarda la legge di Moore siamo ormai al limite delle possibili riduzioni di feature. La soluzione, anche qui prospettata da tutti e sperimentata a oggi solo in modo limitatissimo, consiste nell’invadere la terza dimensione del chip che per ora ha una organizzazione sostanzialmente planare. La prima innovazione abbastanza semplice ha riguardato le memorie realizzate in più strati sovrapposti. Molto più interessante è la costruzione già sperimentata di CMOS i cui transistor pull-up e pull-down sono costruiti uno sopra l’altro in due zone sovrapposte del chip: struttura ancora in fase sperimentale che quasi dimezza l’area del chip ma complica le connessioni.
Inutile dire che le tecnologie di produzione dovranno essere trasformate in modo sostanziale. L’approccio più desiderabile su cui si scommette, limitato a studi di fattibilità ma non ancora a progetti esecutivi, è connesso al problema dello in-memory computing: uno strato di celle di memoria costruito immediatamente sopra uno strato di calcolo ridurrebbe drasticamente la lunghezza dei collegamenti tra di essi, riducendo tra l’altro l’energia termica generata che non è semplice dissipare dall’interno di un chip tridimensionale. Le previsioni di oggi indicano l’anno 2025 come inizio dell’era in cui queste soluzioni entreranno commercialmente in gioco. Uno sviluppo tridimensionale con valori delle tre dimensioni confrontabili tra loro sembra ancora un obiettivo molto lontano, anche se il mondo dei chip non ha mancato di stupirci negli anni.
Qualche considerazione conclusiva
Concludiamo questa carrellata con qualche informazione sul mondo della produzione. Nella figura 6 è mostrato il chip commerciale su cui è integrato un intero processor, contenente il massimo numero di transistor tra quelli disponibili nel momento in cui questo articolo viene scritto: si chiama M1 Ultra e vi convivono 114 miliardi di transistor. Si noti che la struttura di un intero processor compresi i circuiti di input/output è incomparabilmente più complessa di quella altamente ripetitiva di una memoria che può essere integrata con un numero di transistor anche maggiore.

Figura 6
Il chip M1 Ultra della Apple, composto da due M1 Max integrati insieme, contiene 114 miliardi di transistor [6].
M1 Ultra è costruito su progetto della Apple dalla Taiwan Semiconductor Manufacturing Company (TSMC), la più grande del mondo nella produzione di chip, ma mettere a confronto le diverse compagnie di produzione non è cosa ovvia. Le più grandi sono TSMC, Samsung, Intel e IBM con differenze tra gli investimenti: nella produzione primeggiano le prime due e in ricerca e sviluppo le seconde. Ma anche Global Foundries, NTT, Toshiba e varie altre partecipano attivamente al gioco tecnologico e scientifico, e tra queste è doveroso citare la italo-francese STMicroelectronics (STM) nata dalla fusione tra l’italiana SGS e la francese Thomson. In particolare la SGS, da cui proveniva Federico Faggin prima di trasferirsi negli Stati Uniti, è stata insignita nel maggio 2021 del IEEE Milestone per “Multiple Silicon Technology on a Chip, 1985”6. Non eccellono ancora le compagnie cinesi, pur producendo chip in grandi quantità in particolare per i telefoni cellulari, perché attriti politici non gli consentono di ottenere il software di progetto e le apparecchiature di produzione più avanzate prodotti in USA, Europa e Giappone.
Interessanti tabelle di dati tecnico-economici sui transistor prodotti oggi si trovano sulle riviste del settore, in particolare citiamo l’articolo [5]; in atti di congressi specializzati; e sui documenti di produttori di chip e di agenzie di valutazione. Tra queste meritano una menzione particolare le agenzie di marketing IC Insight e TechInsight, e sopra tutte la International Roadmap for Devices and Systems (IRDS) cui partecipano esperti internazionali sotto il patrocinio dell’IEEE con il proposito di stimolare l’innovazione e la ricerca [7].
Concludiamo con due dati crudi. Il primo, pubblicato da IC Insight, mostra che nel 2022 le spese complessive nel mondo per ricerca e sviluppo di chip hanno superato 850 miliardi di dollari e la previsione per il 2025 sfiora i 100 miliardi, mentre il rapporto tra queste spese e i ricavi della vendita dei chip si è assestato attorno al 13 % nel 2022 ed è previsto stabile nei prossimi anni. Il secondo, pubblicato da TechInsigth, è che nel 2022 sono stati prodotti circa 21021 (due miliardi di trilioni) di transistor: circa 250 miliardi per ogni abitante del nostro pianeta.
E, a titolo di cronica spassosa, si può stimare che l’area complessiva dei circuiti integrati esistenti oggi si avvicini ai cento milioni di metri quadrati.
BIBLIOGRAFIA
[1] Perry, T.S. (2020). “How the father of FinFETs helped save Moore’s law”. Spectrum IEEE, May 2022, 47-51.
[2] Hénin, S. (2019). “Due anniversari da ricordare”, Mondo Digitale, No 86, Novembre 2019, rubriche Storia dell’Informatica.
[3] Moore, G.E. (1965). “Cramming More Components onto Integrated Circuits”, Electronics Magazine, 38 (8), 114–117.
[4] Dally, W. e Vishkin, U. (2022). “On the model of computation”, Communications of the ACM, 65 (9), 30-32.
[5] Cass, S. (2022). “The ultimate transistor timeline”, Spectrum IEEE, December 2022, 29-31.
[7] https://www.icinsights.com, https://www.techinsights.com, https://irds.ieee.org/editions/2022
- A parte la profondità di pensiero, John Bardeen era noto per la gentilezza di tratto. È stato l’unico studioso a ottenere per due volte il premio Nobel per la fisica: il secondo nel 1972 per “la teoria generale della superconduttività”. Lasciata la AT&T divenne professore della University of Illinois dove l’autore di questo articolo ebbe l’onore di incontrarlo come collega. Da tempo non è più tra noi. ↩︎
- Gli operatori NAND e NOR furono introdotti come “operatori universali” dal matematico Henry Maurice Sheffer nel 1913. Il loro enorme interesse pratico si è rivelato con la nascita dei transistor ↩︎
- La “logica di tensioni” in cui i valori 0, 1 sono associati alle tensioni di ingresso e uscita dei transistor non deve for credere che nel circuito non circolino correnti. Imponendo una tensione sul gate si carica il condensatore gate/substrato attraverso una corrente. Similmente la tensione di uscita del transistor alimenterà un circuito successivo. ↩︎
- Nel 1968 Moore lasciò la Fairchild per fondare la Intel assieme a Noyce. È mancato nel marzo 2023 a novantaquattro anni, ma fino all’ultimo ha rilasciato interessantissime interviste. ↩︎
- Ricordiamo che la feature si riferisce ai dettagli di minima grandezza. Secondo molti esperti un parametro più significativo per il confronto tra processi produttivi è la lunghezza del canale che in una tecnologia a 2 nm dovrebbe attestarsi attorno a 7nm. ↩︎
- Il Milestone è conferito dall’istituto americano IEEE in ricordo di momenti fondamentali nello sviluppo scientifico e tecnologico. La dedica a SGS recita: “SGS (now STMicroelectronics) pioneered the super-integrated silicon-gate process combining Bipolar, CMOS, and DMOS (BCD) transistors in single chips for complex, power-demanding applications.” I transistor DMOS (D sta per double-diffused per la loro struttura sul silicio) sono transistor di potenza di cui, come per altri tipi, non vi è spazio per parlare qui. ↩︎
Fabrizio Luccio. Laureato in Ingegneria Elettronica al Politecnico di Milano ha lavorato inizialmente all’Olivetti, è stato ricercatore presso l’MIT, l’IBM in USA e la NTT in Giappone, professore delle University of Southern California, New York University, University of Illinois e National University of Singapore. Tornato in Italia ha insegnato fino al 2010 nell’Università di Pisa ove è oggi professore emerito. È Life Fellow dell’IEEE e professore onorario della Technical University di Xi’an e della University of Nanning in Cina. Ha diretto un’intensa cooperazione scientifica con paesi in via di sviluppo per conto dell’Unesco.

