Sommario
Il testo esplora alcune delle potenzialità dell’intelligenza artificiale (AI) in ambito educativo rese possibili grazie alla capacità di questa tecnologia di categorizzare i dati. Attraverso l’analisi dei dati e l’apprendimento automatico, l’AI può migliorare i modelli sociali esistenti e offrire analisi personalizzate. Si esaminano allora le sfide e le opportunità dell’AI nel personalizzare percorsi di apprendimento, valutare le competenze e persino rilevare problemi come depressione e dipendenza da internet, anche nei loro stadi più embrionali. Gli autori sottolineano l’importanza di affiancare l’AI all’approccio umano, utilizzandola come supporto decisionale e non come sostituto.
Abstract
The text explores some of the potentialities of artificial intelligence (AI) in the educational field, made possible by this technology’s ability to categorize data. Through data analysis and machine learning, AI can improve existing social models and provide personalized analyses. It examines the challenges and opportunities of AI in personalizing learning paths, assessing competencies, and even detecting issues such as depression and internet addiction, even in their early stages. The authors emphasize the importance of integrating AI with the human approach, using it as a decision-making support rather than a replacement.
Keywords
artificial intelligence; clustering; classification; machine learning; personalized teaching.
1. Introduzione
In questo documento gli autori intendono descrivere alcune possibili applicazioni dell’AI nel campo educativo. Inizialmente, verranno illustrati i principi chiave dell’AI, del machine learning e degli apprendimenti supervisionato e non supervisionato. Successivamente, verranno analizzati alcuni dei modelli socio-pedagogici più diffusi, come i metodi di insegnamento e le intelligenze multiple, insieme alle problematiche più comuni che affliggono gli adolescenti. I concetti descritti saranno poi integrati nella terza parte del testo, dove verrà mostrato come l’AI possa essere utilizzata con successo per individuare i migliori metodi di insegnamento, identificare le diverse intelligenze presenti in una classe e rilevare precocemente alcune problematiche. Infine, nella parte conclusiva del testo, verranno esaminati i pregi e i limiti di questi sistemi, sottolineando come l’AI debba essere vista come un mezzo di supporto alle decisioni, e non come un sostituto dell’occhio attento di docenti e del personale scolastico.
2. Metodologia
I dati e le informazioni presentati in questo documento sono stati raccolti attraverso un’analisi approfondita della letteratura scientifica disponibile sui temi trattati, utilizzando i motori di ricerca Scopus e Google Scholar per individuare le pubblicazioni più rilevanti. Sono stati presi in considerazione articoli scientifici che mettono in relazione le scienze sociali con l’AI, articoli provenienti dalla sfera delle scienze sociali, focalizzati sull’educazione e sulle problematiche giovanili, e articoli riguardanti l’intelligenza artificiale, con particolare attenzione ai suoi aspetti tecnici. Successivamente, gli autori hanno formulato ipotesi su come le sfere delle scienze sociali e dell’AI possano trovare nuovi punti di incontro, ipotizzando potenziali applicazioni dell’AI per risolvere problematiche educative e personalizzare i percorsi di apprendimento. Le ipotesi presentate si basano su supposizioni teoriche, in mancanza di verifiche pratiche o studi empirici diretti. Le sfide e le problematiche legate all’utilizzo dell’AI nell’educazione sono state esplorate dagli autori come speculazioni basate sulla letteratura disponibile e non confermate da sperimentazioni reali (Toto et al., 2023).
3. Che cos’è l’intelligenza artificiale?
L’intelligenza artificiale (AI) è un campo dell’informatica che si occupa di creare sistemi informatici in grado di eseguire compiti che richiedono tipicamente una forma di intelligenza come quella umana (Sarker, I. H., 2022).
In realtà non è solo all’intelligenza umana quella a cui ci si ispira, ma più in generale a tutti i processi delle scienze naturali che mostrano una qualche forma di intelligenza (Sgarro, G. A. et al., 2024). Ad esempio, è considerabile AI il modellizzare il funzionamento di una colonia di formiche per risolvere problemi di ottimizzazione di percorsi (Sgarro, G. A., Grilli, L., 2024), o il simulare i processi di crossover e di mutazione delle colture cellulari durante la riproduzione per trovare il giusto mix di ingredienti per creare una miscela efficace e così via (Figura 1) (Sgarro, G. A. et al., 2024; Sgarro, G. A., Grilli, L., 2023). L’intelligenza artificiale, quindi, non è altro che la modellizzazione di atteggiamenti intelligenti osservati nel mondo che ci circonda allo scopo di risolvere problemi di varia natura (Fetzer, J. H., 1990; Wang, P., 2019).
Figure 1: Immagine artistica che mostra cervelli, insetti e genomi collegati alle macchine. L’idea è quella di mostrare come alcuni principi di funzionamento di questi elementi sono ciò che è alla base dell’AI. Immagine creata con tecnologia DALL-E 3, Copilot, Microsoft Bing (www.bing.com, ultimo accesso giugno 2024).
Di solito, gli algoritmi AI sono progettati per imitare le capacità di risoluzione di questi sistemi, come il ragionamento, l’apprendimento, la ricerca del cibo, la lotta per la sopravvivenza, il problem solving, il riconoscimento di modelli e il linguaggio naturale (Górriz, J. M. et al., 2020). L’obiettivo dell’AI è quello di sviluppare algoritmi e modelli che consentano alle macchine di svolgere attività complesse in modo autonomo, aprendo la strada a una vasta gamma di applicazioni in diversi settori, tra cui la medicina, la finanza, l’automazione industriale, la robotica, i trasporti e molti altri (Sarker, I. H., 2022).
3.1 Machine Learning (ML)
Il machine learning è una sottodisciplina dell’intelligenza artificiale che si concentra sullo sviluppo di algoritmi e modelli in grado di imparare dai dati e migliorare le proprie prestazioni nel tempo senza necessità di programmazione esplicita (Das, S. et al., 2015; Pramod, A. et al., 2021). In pratica, il machine learning permette ai computer di riconoscere pattern nei dati e trarre conclusioni o prendere decisioni basate su questi pattern, senza richiedere istruzioni dettagliate dagli sviluppatori (El Naqa, I., Murphy, M. J., 2015).
Le due parole chiave per comprendere questo concetto sono “learning” e “data”. La caratteristica principale degli algoritmi di machine learning è infatti l’utilizzo dei dati per risolvere problemi. Per esempio, supponiamo di voler insegnare a un computer a risolvere delle equazioni:
- un algoritmo tradizionale seguirebbe una serie di passaggi predefiniti: 1) porta l’incognita a sinistra dell’uguale, 2) trova il minimo comune denominatore se ci sono frazioni a destra, e così via;
- un algoritmo di machine learning, invece, utilizza un database di equazioni già risolte per dedurre autonomamente le regole necessarie per risolverle.
Ma come fanno questi algoritmi di machine learning a “imparare” le regole dai dati? Prima di rispondere a simile imperativo, però, è importante introdurre un concetto fondamentale: ci sono diversi approcci al machine learning, tra questi i più famosi sono l’apprendimento supervisionato e l’apprendimento non supervisionato (Figura 2).
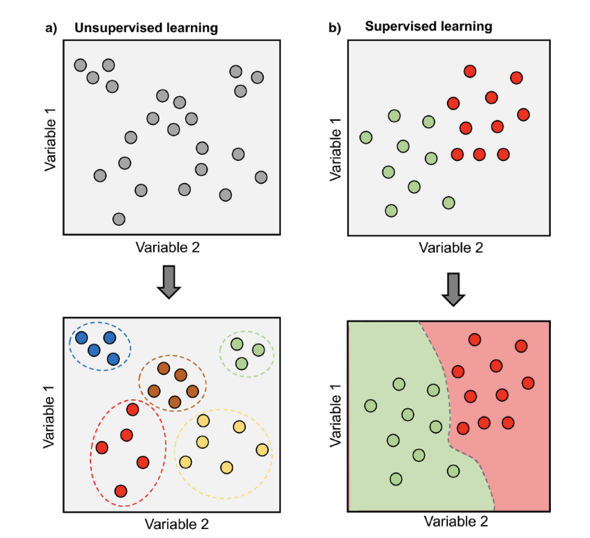
Figura 2: A sinistra, lo schema di funzionamento di un algoritmo non supervisionato; a destra, quello di un algoritmo supervisionato. Entrambi gli approcci classificano oggetti, ma come spiegato in seguito, lo fanno in modo diverso. Immagine tratta da Morimoto, J., Ponton, F., 2021.
3.2 Tipi di apprendimento nel Machine Learning
Due tra i più importanti approcci del machine learning sono l’apprendimento supervisionato e quello non supervisionato.
3.2.1 Apprendimento supervisionato
In questo approccio, il modello viene addestrato su un insieme di dati etichettati, dove ogni esempio di input è associato a una corrispondente etichetta di output. Il modello impara a fare previsioni o a prendere decisioni analizzando gli esempi etichettati forniti durante il processo di addestramento (Cunningham, P. et al., 2008; Igual, L., Seguí, S., 2024).
Ad esempio, in ambito medico per addestrare una rete neurale a identificare la presenza di un tumore maligno in un’immagine radiografica, si potrebbe procedere in questo modo:
- Raccogliere un gran numero di immagini radiografiche, idealmente centinaia o migliaia. Metà delle immagini rappresentano soggetti con tumori maligni, mentre l’altra metà rappresenta soggetti senza tumori.
- Fornire queste immagini alla rete neurale una alla volta. Durante questa fase, la rete tenta di determinare se l’immagine contiene un tumore. Se sbaglia, modifica leggermente i suoi parametri interni.
- Questo processo di addestramento continua per tutte le immagini disponibili. Con il tempo, la rete inizia a commettere sempre meno errori, imparando gradualmente a riconoscere i pattern associati alla presenza di tumori.
- Al termine dell’addestramento, i valori dei parametri della rete vengono “congelati” e la rete può essere utilizzata per classificare nuove immagini radiografiche con successo (Figura 3) (Chowdhury, A. et al., 2021).
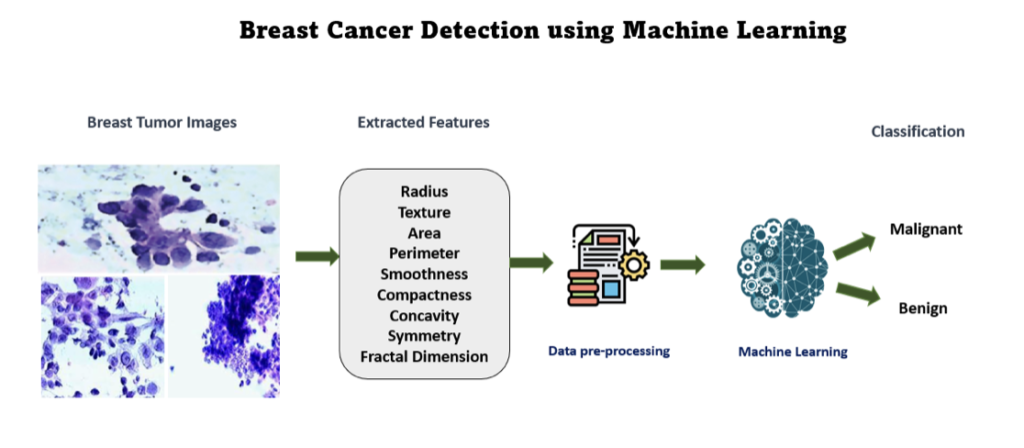
Figura 3: Schema di funzionamento di un classificatore per tumori. In questo caso, si misurano i valori di alcuni parametri dalle immagini di mammografia, come raggio, texture, area, ecc. Questi dati vengono prima elaborati e poi utilizzati per addestrare il classificatore a individuare le immagini tumorali. Immagine tratta da www.wisdomml.in (ultimo accesso giugno 2024).
3.2.2 Apprendimento non supervisionato
In questo caso, il modello viene addestrato su un insieme di dati non etichettati e ha lo scopo di trovare pattern o strutture intrinseche nei dati senza la guida di etichette. Questo tipo di apprendimento è spesso utilizzato per l’analisi dei dati e il clustering (Barlow, H. B., 1989; Hastie, T. et al., 2009).
Si supponga di avere gli stessi dati dell’esempio precedente, ma senza etichette che indicano quali immagini contengono tumori. Ciò che conta è che le variabili che li descrivono siano correlate ai tumori. Utilizzando tecniche definite “di clustering”, il modello può identificare pattern o gruppi di immagini simili all’interno del dataset (Sgarro, G. A. et al. 2023a; Sgarro et al. 2023b). Questo potrebbe permettere non solo di discriminare i soggetti con tumori maligni dai soggetti sani, ma anche di scoprire sottogruppi di pazienti con caratteristiche simili, come sottotipi di tumori all’interno del gruppo “tumore”.
Ad esempio, considerando lo stesso esempio del caso in ambito medico: si ipotizzi di voler addestrare una rete neurale a identificare la presenza di un tumore maligno in un’immagine radiografica. Ecco come si potrebbe procedere:
- Raccogliere un gran numero di immagini radiografiche, idealmente centinaia o migliaia. Metà delle immagini rappresentano soggetti con tumori maligni, mentre l’altra metà rappresenta soggetti senza tumori.
- Fornire queste immagini alla rete neurale senza etichette, cioè senza indicare quali immagini contengono tumori. La rete utilizza tecniche di clustering per suddividere in modo intelligente le immagini, basandosi sui parametri fisici delle immagini stesse.
- Dopo la suddivisione, interpretare i dati per verificare se la rete ha individuato correttamente i gruppi significativi. In questo caso, è bene controllare se la rete è riuscita a classificare correttamente le immagini di tumori e non tumori “senza saperlo”. Inoltre, analizzare se i raggruppamenti ottenuti corrispondono a sottotipi specifici di tumori (Figura 4) (Sgarro et al., 2023b).
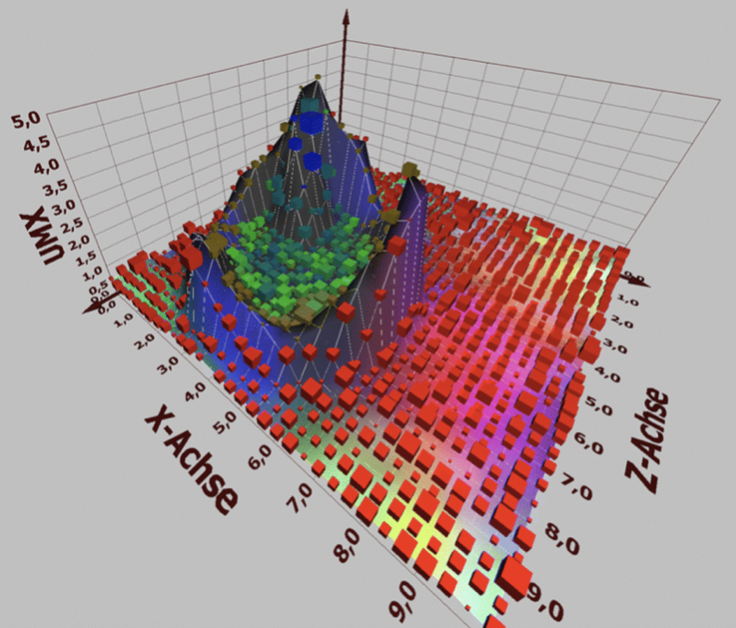
Figura 4: Esempio di rappresentazione dei risultati di un algoritmo non supervisionato nello studio dell’Epatite C. I cluster verdi e blu rappresentano pazienti con diagnosi confermata di epatite, mentre i cubi rossi e marroni indicano pazienti con diagnosi negativa. Immagine tratta da Reiser, M. et al. 2019.
3.2.3 Nota
Machine learning è diverso da reti neurali, i due concetti NON sono intercambiabili. Negli esempi sopra riportati si è voluto utilizzare il termine reti neurali proprio per mettere in evidenza in questo punto del documento questo concetto, in modo da fissarlo meglio. Le reti neurali possono essere algoritmi di ML, ma non è vero che tutti gli algoritmi di ML sono reti neurali. Oltre alle reti neurali, esistono molti altri algoritmi di machine learning che possono essere utilizzati per l’apprendimento supervisionato e non supervisionato (Figura 5). Alcuni esempi includono SVM (Support Vector Machines), alberi decisionali, foreste casuali e K-Means. Le reti neurali sono modelli computazionali di AI ispirati al funzionamento del cervello umano e sono molto diffuse per risolvere certi tipi di problemi, ma è importante non fare confusione, poiché quest’ultime sono solo una parte di quel vasto campo che è il machine learning (Helm, J. M. et al., 2020).
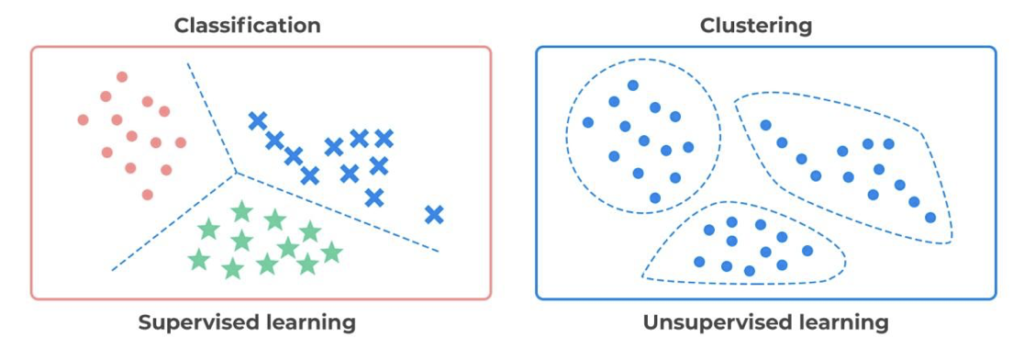
Figura 5: A sinistra, una rappresentazione del concetto di classificazione; a destra, quello di clustering. La differenza è che nel primo caso i dati sono già etichettati e il classificatore deve inserire un elemento nella classe giusta, mentre nel secondo caso non ci sono etichette, e l’algoritmo ha lo scopo di definire cluster separati in modo “matematicamente intelligente”. Figura tratta da Saini, S., 2021.
4 Insegnare, apprendere, e conoscere i problemi: le tre chiavi di un buon insegnante
Ogni persona è unica, sia geneticamente che fenotipicamente. Questo principio si applica anche all’apprendimento: studenti diversi apprendono in modi diversi. Per ottimizzare l’apprendimento di uno studente e accelerarne il progresso è essenziale personalizzare il processo educativo. Ogni studente ha una “chiave di apprendimento” personale, ovvero impara meglio quando il materiale è presentato in un modo specifico piuttosto che in un altro. Per questo motivo, alcuni pedagogisti hanno sviluppato varie forme di insegnamento e tentato di classificare le intelligenze.
4.1 Metodi di insegnamento
Alcuni approcci educativi fondamentali della pedagogia (Figura 7) sono:
- Cognitivismo: è un approccio educativo che si basa sullo studio dei processi mentali e cognitivi coinvolti nell’apprendimento. Questo approccio pone enfasi sull’importanza delle strutture cognitive individuali degli studenti e sull’elaborazione delle informazioni da parte del cervello. Secondo il cognitivismo, gli studenti elaborano attivamente le informazioni, organizzandole, memorizzandole e recuperandole in modo significativo. Gli insegnanti che adottano un approccio cognitivista utilizzano strategie come la suddivisione delle informazioni in unità più piccole, la fornitura di modelli e schemi concettuali, l’insegnamento delle strategie di risoluzione dei problemi e l’uso di tecniche di recupero mnemonico per facilitare l’apprendimento (Ertmer, P. A., Newby, T. J., 2013).
- Sociocostruttivismo: è un approccio educativo che enfatizza il ruolo dell’interazione sociale e dell’ambiente culturale nell’apprendimento degli individui. Questo approccio è basato sulla teoria secondo cui gli individui costruiscono attivamente la loro conoscenza attraverso l’interazione con gli altri e con l’ambiente circostante. Secondo il sociocostruttivismo, l’apprendimento è un processo sociale e collaborativo in cui gli studenti si impegnano in attività di costruzione del significato insieme ad altri individui. Gli insegnanti che adottano un approccio sociocostruttivista promuovono l’apprendimento attraverso l’interazione sociale, l’attività collaborativa, la risoluzione di problemi autentici e l’uso di strumenti culturali e tecnologici per facilitare l’apprendimento condiviso e la costruzione del significato (Saleem, A. et al., 2021).
- Costruttivismo: è un approccio educativo che enfatizza il ruolo attivo degli studenti nel costruire la propria conoscenza attraverso l’esperienza e l’interazione con l’ambiente circostante. Secondo il costruttivismo, gli studenti costruiscono il loro sapere attraverso la riflessione, la risoluzione dei problemi, l’attività autonoma e la collaborazione con gli altri (Ertmer, P. A., Newby, T. J., 2013; Bada, S. O., Olusegun, S., 2015).
- Pedagogia critica: è un approccio educativo che si concentra sull’analisi critica delle strutture di potere e delle disuguaglianze sociali presenti nella società in modo da cerca di aiutare gli studenti a confrontare e porre domande riguardanti i processi di dominazione e pratiche, abitudini, presupposti, miti, costruzioni sociali e ideologie dominanti. Questo approccio mira a sviluppare negli studenti una consapevolezza critica delle ingiustizie sociali e a incoraggiarli a diventare agenti di cambiamento sociale attraverso l’azione e il pensiero critico (Aliakbari, M., Faraji, E., 2011).
- Apprendimento esperienziale: è un approccio educativo che mette l’accento sull’importanza dell’esperienza diretta e dell’apprendimento attraverso l’azione. Gli studenti imparano facendo, partecipando a attività pratiche, esperienze sul campo, stage, apprendimento basato su progetti e altre attività che consentono loro di applicare la conoscenza in contesti reali (Kolb, D. A., 2014).
- Apprendimento basato sull’indagine: è un approccio educativo che incoraggia gli studenti a porre domande, esplorare argomenti di interesse personale e condurre ricerche autonome. Questo approccio promuove l’attività di apprendimento degli studenti, la curiosità e la capacità di pensare in modo critico e indipendente (Gholam, A. P., 2019).
- Pedagogia della fiducia: è un approccio educativo che si concentra sull’importanza di creare un ambiente di apprendimento inclusivo, rispettoso e fiducioso in cui gli studenti si sentono sicuri di esprimersi, sperimentare e prendere rischi nel processo di apprendimento (Figura 6) [30].
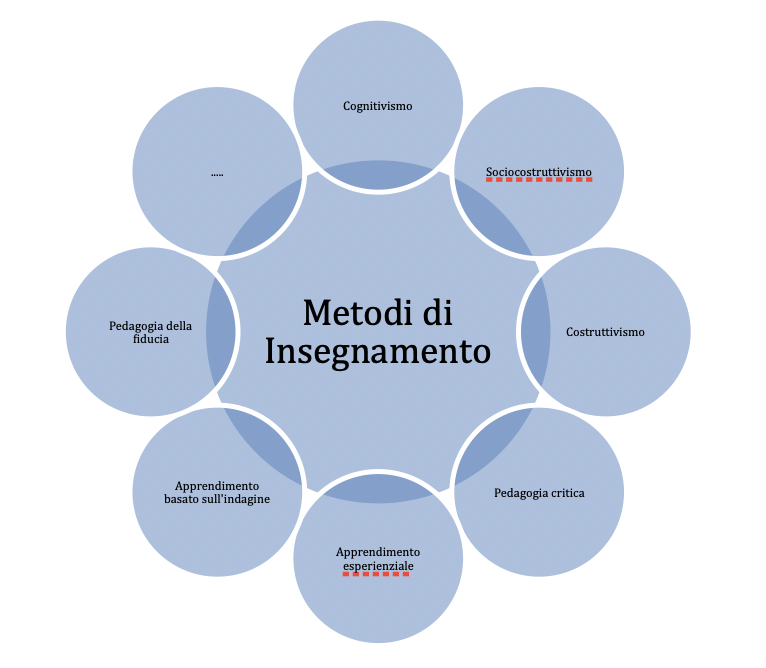
Figura 6: Rappresentazione grafica di alcuni dei metodi di insegnamento più diffusi proposti in letteratura scientifica.
4.2 Modalità di apprendimento
Mentre alcuni studiosi hanno proposto metodologie di insegnamento, altri hanno proposto delle classificazioni degli studenti sulla base della loro modalità di apprendimento (Figura 7). Una delle classificazioni più famose è quella proposta da Gardner nel 1893. Le intelligenze multiple di Gardner sono una teoria introdotta dallo psicologo statunitense nel suo libro “Frames of Mind: The Theory of Multiple Intelligences”. Secondo Gardner, l’intelligenza non può essere semplicisticamente ridotta a un’unica capacità generale, ma piuttosto è composta da diverse forme di intelligenza, ognuna delle quali è indipendente dalle altre. Gardner ha identificato originariamente sette intelligenze multiple, e in seguito ne ha aggiunto un’ottava (Gardner, H. E., 2000; Phillips, H., 2010). Queste intelligenze sono:
- Linguistica: capacità di utilizzare il linguaggio in modo efficace, sia scritto che parlato.
- Logico-matematica: capacità di ragionare logicamente, risolvere problemi matematici complessi e applicare il pensiero scientifico.
- Spaziale: capacità di comprendere e manipolare oggetti nello spazio, visualizzare immagini mentali e navigare in ambienti tridimensionali.
- Corporeo-cinestetica: capacità di utilizzare il proprio corpo in modo coordinato e abile, sia per attività fisiche che per espressioni artistiche come danza o arti performative.
- Musicale: capacità di apprezzare, comprendere e produrre musica, nonché di riconoscere e manipolare i pattern sonori.
- Interpersonale: capacità di comprendere e interagire efficacemente con gli altri, mostrando empatia, cooperazione e leadership.
- Intrapersonale: capacità di comprendere e gestire i propri pensieri, emozioni e comportamenti, sviluppando una buona autostima e una forte consapevolezza di sé.
- Naturalistica: capacità di comprendere e apprezzare il mondo naturale, osservando, riconoscendo e classificando gli elementi presenti nell’ambiente naturale.
Secondo la teoria delle intelligenze multiple, ciascuna persona possiede un mix unico di queste intelligenze e può eccellere in una o più di esse. Gardner ha sottolineato l’importanza di riconoscere e coltivare le diverse intelligenze negli individui, anziché concentrarsi esclusivamente su misurazioni standardizzate di intelligenza come il QI (Gardner, H. E., 2000). Questa prospettiva ha avuto un impatto significativo sulla pedagogia e sull’educazione, incoraggiando gli insegnanti a utilizzare approcci più diversificati e inclusivi per soddisfare le esigenze di tutti gli studenti.
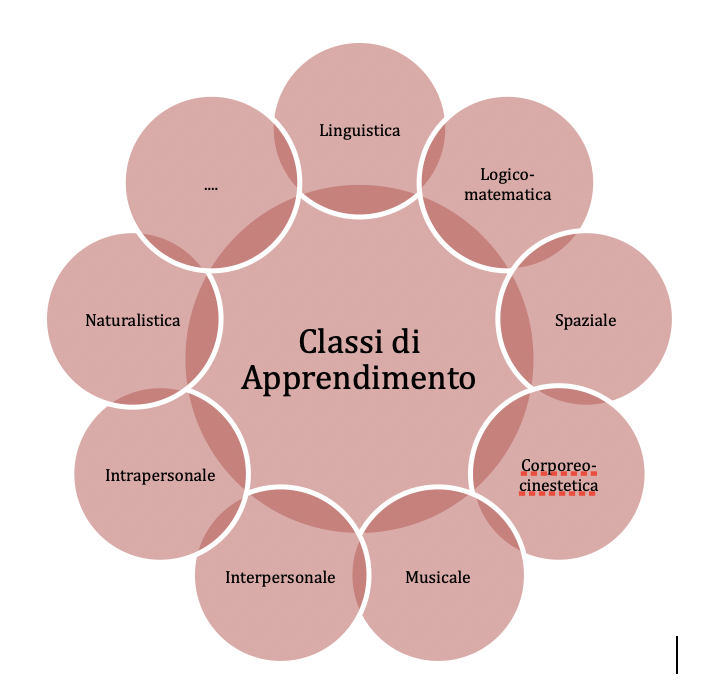
Figura 7: Rappresentazione grafica di alcune delle classi di apprendimento più diffuse proposte in letteratura scientifica.
4.3 Problematiche individuali di varia natura
Infine, è fondamentale ricordare che gli studenti non sono macchine. Anche se esistesse un metodo perfetto per insegnare loro in modo ottimale, non basterebbe catalogarli e adattare l’insegnamento alle loro esigenze per garantirne il benessere. Ogni studente è una persona estremamente complessa, in continua evoluzione e cambiamento, che può affrontare talvolta momenti difficili tra cui la perdita di una persona cara, crisi esistenziali, dipendenze o depressione. In questi casi, la scuola e gli insegnanti rivestono un ruolo cruciale. Riconoscere e affrontare tempestivamente i problemi che ostacolano il rendimento scolastico non solo aiuta a mantenere buoni risultati accademici, ma può anche migliorare significativamente il benessere complessivo dello studente, permettendogli di trovare felicità e soddisfazione anche al di fuori dell’ambiente scolastico. Considerando questo aspetto, le performance scolastiche degli adolescenti possono deteriorarsi per una serie di motivi complessi e multidimensionali (Verboom, C. et al., 2014; Skinner, E. A., Saxton, E. A., 2019). Alcuni dei principali fattori (Figura 8) possono riguardare:
- Cambiamenti fisici e ormonali: durante l’adolescenza si affrontano cambiamenti fisici e ormonali significativi che possono influenzare il loro benessere emotivo e cognitivo. Questi cambiamenti possono causare stanchezza, sbalzi d’umore e difficoltà di concentrazione, che a loro volta possono influire sulle performance scolastiche (Alghadir, A. H. et al., 2020).
- Pressione sociale: gli adolescenti possono essere sottoposti a pressioni sociali significative dai loro coetanei, che possono influenzare il loro comportamento e le loro priorità. La ricerca di accettazione sociale e l’adattamento ai gruppi dei pari possono portare gli adolescenti a trascurare gli impegni scolastici e a concentrarsi su altre attività che ritengono più importanti o gratificanti (Moldes, V. M. et al., 2019).
- Stress e ansia: gli adolescenti possono sperimentare livelli elevati di stress e ansia legati a molteplici fattori, come la pressione accademica, i conflitti familiari, le relazioni interpersonali e le preoccupazioni sul futuro. Lo stress e l’ansia possono interferire con la capacità degli adolescenti di concentrarsi, apprendere e performare bene a scuola (Anila, M. M., Dhanalakshmi, D., 2016; Kiselica, M. S. et al., 2019).
- Problemi familiari: situazioni familiari come divorzio dei genitori, conflitti familiari, instabilità domestica, abuso o trascuratezza possono avere un impatto significativo sulle performance scolastiche degli adolescenti. Gli stress familiari possono influire sul benessere emotivo degli adolescenti e sulla loro capacità di concentrarsi e impegnarsi negli studi (Rodgers, K. B., Rose, H. A., 2001).
- Distrazioni tecnologiche:la tecnologia e i dispositivi digitali possono essere una fonte di distrazione significativa per gli adolescenti, con un’ampia gamma di dispositivi e applicazioni che competono per la loro attenzione. Passare troppo tempo su dispositivi digitali può ridurre il tempo dedicato allo studio e alla preparazione scolastica (Dontre, A. J., 2021).
- Problemi di salute mentale: gli adolescenti possono sviluppare problemi di salute mentale come depressione, ansia, disturbi dell’umore o disturbi dell’attenzione che possono influenzare negativamente il loro andamento scolastico. La mancanza di supporto e risorse per affrontare questi problemi può peggiorare ulteriormente le loro performance scolastiche (McLeod, J. D. et al., 2012).
- Problemi di apprendimento o disabilità: gli adolescenti con problemi di apprendimento o disabilità possono incontrare sfide aggiuntive nel contesto scolastico che influenzano le loro performance accademiche. La mancanza di supporto adeguato e di interventi personalizzati può limitare le opportunità di successo degli studenti con queste condizioni (Lyon, G. R., 1996).
- Mancanza di motivazione o interesse:gli adolescenti possono sperimentare una mancanza di motivazione o interesse per la scuola, soprattutto se non vedono la rilevanza o l’utilità degli argomenti insegnati. La mancanza di connessione emotiva con il materiale didattico può portare al disimpegno e al peggioramento delle performance scolastiche (Trigueros, R. et al., 2019).

Figura 8: Rappresentazione grafica di alcune delle problematiche adolescenziali più diffuse proposte in letteratura scientifica
5 AI per l’apprendimento e per prevedere i comportamenti
Esposta una panoramica generale, seppur non esaustiva, su quali possono essere le varie modalità di insegnamento da proporre a lezione, quali possono essere le varie modalità di apprendimento che possono presentare degli studenti e quali sono le varie problematiche che possono essere da ostacolo nel loro percorso di crescita personale, è possibile osservare come l’AI possa essere utilizzata come strumento di ausilio per esperti della formazione per migliorare ulteriormente la qualità dell’insegnamento.
5.1 Personalizzare l’insegnamento con un approccio non supervisionato
Per migliorare la qualità della didattica in una scuola si potrebbe costruire un sistema di personalizzazione dell’insegnamento, basato sull’apprendimento non supervisionato, che utilizzi dati relativi agli studenti correlati alle informazioni sulle intelligenze multiple e sui vari approcci educativi fondamentali della pedagogia. Questo progetto ambizioso può essere realizzato seguendo alcuni passaggi fondamentali:
1. Creazione del dataset: definire come devono essere strutturati i nostri dati. È possibile creare un questionario le cui domande evidenzino una preferenza di apprendimento o di docenza rispetto a un’altra. Ad esempio, si potrebbero organizzare le domande in questo modo:
- Quale delle seguenti frasi spiega meglio questo concetto? 1) Spiegazione per classe linguistica 2) Spiegazione per classe logico-matematica 3)… 8) Spiegazione per classe naturalistica.
- Seleziona il sinonimo della parola X (Linguistica).
- Se Mario ha 5 €, ne presta 2 ad Annalisa, che a sua volta, dopo aver pagato 1,5€ per una pizza, restituisce il resto a Mario, quanti soldi ha Mario? (Logico-matematica).
- Capiresti meglio come si fa la pizza: 1) Osservando uno schema disegnato (Cognitivismo) 2) Facendola tutti insieme in classe (Sociocostruttivismo) 3) Guardando e assistendo un pizzaiolo mentre la prepara (Costruttivismo).
2. Raccolta dei dati: raccogliere informazioni sugli studenti, inclusi dati demografici, punteggi di intelligenze multiple, preferenze di apprendimento e prestazioni accademiche. Si raccomanda, per la raccolta dei dati e se necessario, di assicurarsi di ottenere il consenso informato dagli studenti o dai loro genitori.
3. Clustering degli studenti: applicare delle tecniche di clustering per suddividere gli studenti in gruppi omogenei in base alle loro caratteristiche. Ad esempio, si potrebbe utilizzare un semplice algoritmo chiamato K-Means per identificare gruppi di studenti con caratteristiche simili di intelligenze multiple e/o preferenze di apprendimento.
4. Sviluppo di profili studenti: una volta identificati i gruppi di studenti, sviluppare profili dettagliati per ciascun gruppo, includendo informazioni sulle intelligenze multiple predominanti, le preferenze di apprendimento e le esigenze educative specifiche.
5. Personalizzazione dell’insegnamento: utilizzare i profili degli studenti per adattare l’insegnamento alle esigenze e preferenze di ciascun gruppo. Ad esempio, si potrebbero sviluppare materiali didattici diversificati che si adattano ai diversi stili di apprendimento e offrire opportunità di apprendimento basate sugli interessi e sulle intelligenze predominanti di ciascun gruppo.
6. Valutazione e iterazione: è importante ovviamente valutare regolarmente l’efficacia del sistema di personalizzazione dell’insegnamento e apportare eventuali modifiche o aggiornamenti in base ai feedback degli studenti e ai risultati delle valutazioni [20].
Quello che è in grado di fare l’AI in questo contesto non è quindi dare un’etichetta a uno studente. Al termine di una procedura di clustering, volendo, si può dare un’etichetta e si può dire se uno studente appartiene maggiormente a un gruppo piuttosto che a un altro. Però, piuttosto, volendo leggere bene i risultati, quello che fa l’AI in questo caso è individuare le caratteristiche dei singoli individui e individuare dei pattern statistici ricorrenti, cioè trovare grazie ai dati dei vari questionari, delle caratteristiche comuni di alcuni gruppi di persone, che possono essere utilizzate da un esperto per avere delle indicazioni circa le caratteristiche delle persone che ha di fronte, in modo da studiare delle strategie di insegnamento individuali e di gruppo (Jain, A. K. et al., 2000). Per fare un esempio molto semplice, si può immaginare che attraverso i dati di una classe di 20 persone si venisse a scoprire che:
- Il 60 % di questi ha intelligenza musicali-interpersonali con una predilezione per l’insegnamento di tipo socio-costruttivista;
- Il 40 % di questi ha intelligenza logico-matematica con predilezione per il cognitivismo.
Queste informazioni potrebbero essere un ottimo punto di partenza per strutturare al meglio l’insegnamento, ad esempio cercando di spiegare ogni argomento in almeno due modi diversi, che valorizzino al meglio le caratteristiche degli studenti. In Figura 9 viene riportato un esempio teorico di possibili risultati che potrebbe dare un “clusterizzatore di studenti”.
Figura 9: Rappresentazione grafica di una clusterizzazione di studenti.
5.2 Prevedere i comportamenti con un approccio supervisionato
È difficile trovare un controesempio che neghi la veridicità di questa frase: “Prevenire è meglio che curare”. Infatti, tanto in medicina, quanto in psicologia fino alla pedagogia, quanto prima si rileva un problema, quanto prima il trattamento e la velocità di risoluzione migliorano. Sarebbe quindi utile disporre di un sistema, basato ad esempio su questionari, che permetta di individuare se uno studente soffre di depressione o di identificare le cause di un malessere che potrebbe compromettere il suo rendimento scolastico (come cambiamenti fisici e ormonali, pressione sociale, stress e ansia, ecc.), o meglio ancora, che permetta di “predire”, quindi di presagire, il manifestarsi di certi fenomeni. Avendo questa idea in mente, come è possibile strutturare la ricerca? Come creare il “classificatore”? Ecco un esempio:
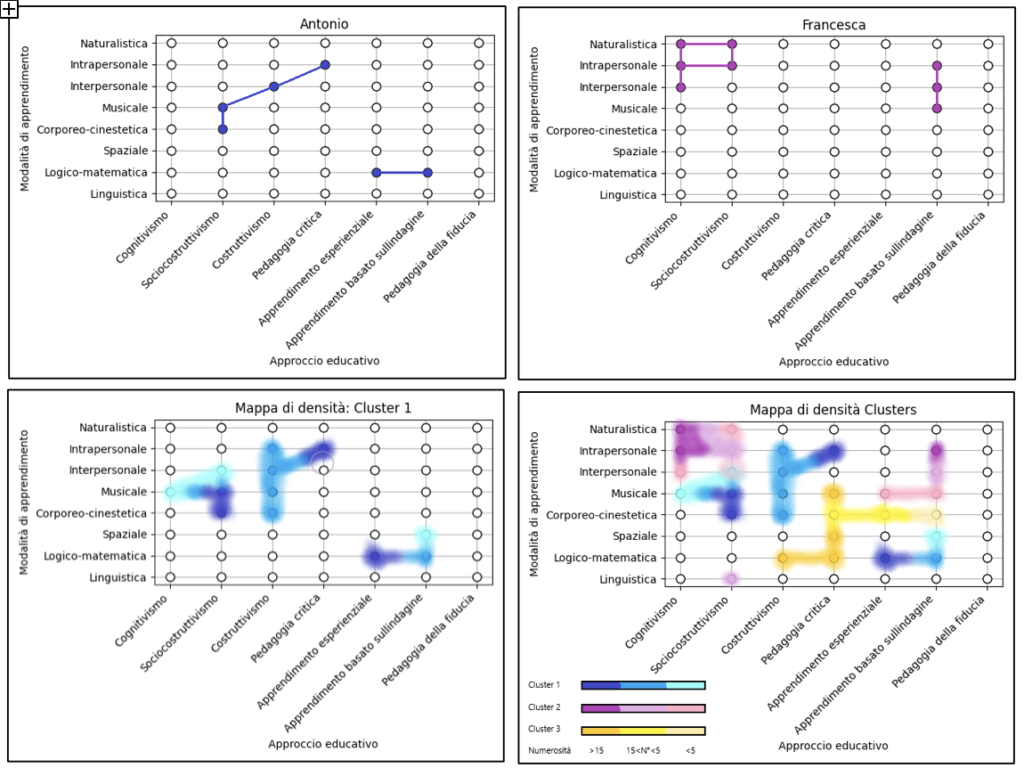
- Creazione del database etichettato: identificare le variabili di input (caratteristiche dello studente, ambiente familiare, salute mentale, abitudini di studio, ecc.) e la variabile di output (motivo legato al peggioramento delle performance scolastiche).
- Ad esempio, alcune domande potrebbero essere: 1) Ritieni sano il tuo ambiente familiare? Sì/No. 2) Quando la professoressa ti interroga alla cattedra, davanti a tutti, provi ansia? Sì/No. 3) Quanto ritieni stressante, da 1 a 5, studiare una materia sapendo che il giorno dopo sarai interrogato? Le etichette finali potrebbero includere: 1) Cambiamenti fisici e ormonali 2) Pressione sociale 3) Stress e ansia.
- È fondamentale disporre di un dataset già etichettato, ovvero di questionari compilati in cui uno psicologo esperto ha già attribuito dei punteggi per ciascuna categoria. Ad esempio, lo studente 1 compila il questionario, poi viene valutato dallo psicologo che assegna i seguenti punteggi: 1) Cambiamenti fisici e ormonali: 2 su 10. 2) Pressione sociale: 8 su 10. 3). Stress e ansia: 7 su 10.
- Creazione del dataset: utilizzare il questionario per raccogliere dati da un campione rappresentativo di studenti. Assicurandosi, come sempre, di ottenere il consenso informato dagli studenti o dai loro genitori per la raccolta dei dati.
- Selezione del modello: scegliere il modello di intelligenza artificiale supervisionato più adatto per il problema. Alcuni modelli comuni includono alberi decisionali, regressione logistica, support vector machine (SVM) o reti neurali artificiali.
- Divisione del dataset: dividere il dataset in un set di addestramento e un set di test. Il set di addestramento verrà utilizzato per addestrare il modello, mentre il set di test servirà per valutarne le performance.
- Addestramento del modello: utilizzare il set di addestramento per addestrare il modello utilizzando l’algoritmo scelto. Il modello imparerà a identificare i pattern tra le variabili di input e l’output desiderato.
- Valutazione del modello: valutare le performance del modello utilizzando il set di test e misurando l’accuratezza del modello nell’individuare i motivi del peggioramento delle performance scolastiche.
- Monitoraggio e aggiornamento: monitorare costantemente le performance del sistema e aggiornarlo periodicamente con nuovi dati e miglioramenti, garantendo che continui a fornire risultati accurati e rilevanti nel tempo (Sgarro, G. A. et al., 2023a).
In questo caso, l’intelligenza artificiale (AI), una volta somministrato il questionario agli studenti, viene impiegata per classificare efficacemente uno studente, ossia per attribuire lo studente a una o più categorie di output definite dallo psicologo. Quest’azione richiama in parte il compito dello psicologo quando si trova di fronte a un paziente. Quando si afferma che una persona soffre di depressione, in pratica la si sta collocando in una categoria. In questa situazione, l’AI cerca di fornire informazioni sotto forma di numeri e punteggi a uno psicologo. Tuttavia, è importante notare che lo psicologo, pur avvalendosi anche di dati numerici durante la somministrazione dei questionari, è consapevole che questi vanno interpretati con cautela. Nei campi della psicologia e della salute mentale, i numeri non definiscono completamente una persona, ma forniscono solo un’indicazione. Tuttavia, questa indicazione può risultare estremamente utile non solo per farsi un’idea di una problematica individuale, ma anche quando si ha a che fare con un grande numero di individui. Immaginando una scuola con 1000 alunni: sarebbe ideale avere un numero adeguato di psicologi, ma spesso ciò non è possibile a causa delle limitazioni di risorse e finanziamenti. Inoltre, non tutti possono permettersi una consulenza privata. La somministrazione di un questionario è un processo relativamente veloce e poco costoso che può essere effettuato su larga scala. Nonostante la sua natura non precisa, può fornire indicazioni sul numero di individui che potrebbero necessitare di assistenza e agevolarne l’individuazione (Figura 10).
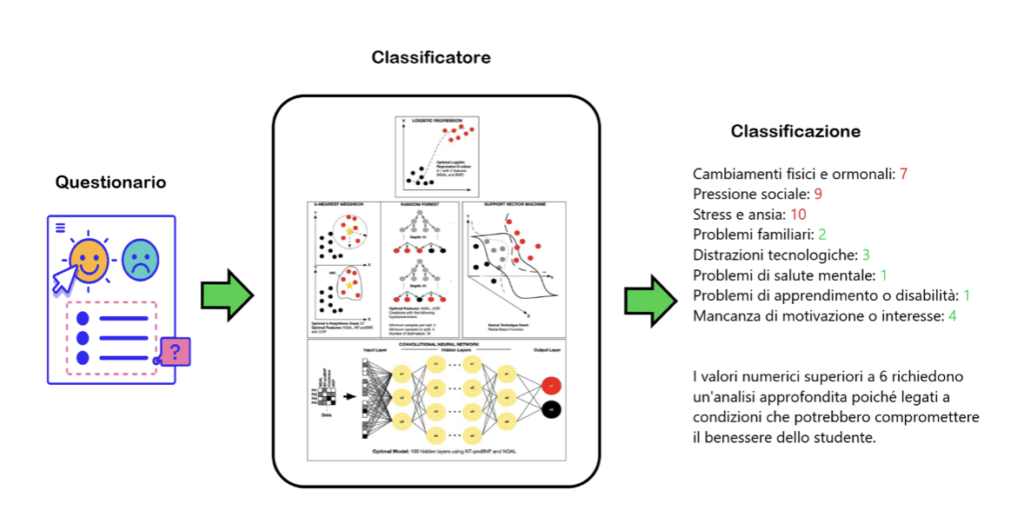
Figura 10: Esempio di funzionamento di un classificatore dopo la fase di training. Lo studente completa il questionario e le sue informazioni vengono elaborate dal classificatore, che definisce una diagnosi. In questo caso è stato ipotizzato un classificatore a più classi, dove per ogni classe si definiscono 10 livelli di appartenenza. Immagine tratta da Rashidi, H. et al., 2020.
6. La macchina come ausilio, non come sostituto
Dopo aver illustrato alcuni esempi concreti di come l’intelligenza artificiale possa essere impiegata nelle scienze sociali, è bene sottolineare che essa non deve essere concepita come un sostituto delle persone in ruoli così delicati, ma piuttosto come un ausilio per gli stessi. È importante ricordare che gli esseri umani non sono macchine, non si basano su semplici zero e uno. In particolare, nelle fasi primarie della vita, è essenziale un coinvolgimento umano per garantire un sano sviluppo emotivo degli individui. Le relazioni umane offrono un calore e un supporto indispensabili durante il processo di crescita. Inoltre, è fondamentale evitare di catalogare le persone con delle etichette. Ogni essere umano è così complesso individualmente che etichettarlo risulterebbe non solo inutile, ma limitativo. Mettendo una persona in una categoria si legherebbe implicitamente il suo percorso di vita a uno schema prestabilito, privandola delle opportunità di esplorare strade alternative che potrebbero favorire il suo sviluppo ottimale. Ogni individuo è unico e continua a evolversi nel corso della propria vita. Certi strumenti come l’intelligenza artificiale e i test prima di questa possono senz’altro migliorare l’approccio all’insegnamento, ma è importante non considerarli come un primo passo verso la sostituzione del personale del settore. Dovrebbero piuttosto essere visti come un mezzo di supporto e di informazione, utili per valutare l’efficacia delle misure adottate da una scuola. Ad esempio, un questionario potrebbe evidenziare un calo nel numero di persone che soffrono di depressione dopo l’implementazione di determinate azioni scolastiche. Tuttavia, è altrettanto importante non considerare questi strumenti come mezzi per prendere decisioni o impartire direzioni. Anche nel contesto delle intelligenze multiple, sarebbe errato escludere approcci costruttivisti semplicemente perché non emergono studenti con quelle specifiche caratteristiche.
7. Conclusione
Da ultimo, è importante lanciare un caloroso appello. La rivoluzione dell’AI è ormai in corso: prima o poi questa entrerà con prepotenza in ogni settore ove applicabile, e tale avanzamento sarà un processo inesorabile. La cosa migliore da fare come esseri umani, come specialisti del settore, non è accettarla passivamente, e neanche ostacolarla, ma imparare a conoscerla ed insegnare ad utilizzarla al meglio (Figura 11).
«Sapientia est potentia».

Figura 11: Immagine artistica che rappresenta l’AI al servizio dell’umanità. Immagine creata con tecnologia DALL-E 3, Copilot, Microsoft Bing (www.bing.com, ultimo accesso giugno 2024).
Riferimenti bibliografici
- Alghadir, A. H., Gabr, S. A., Iqbal, Z. A. (2020). “Effect of gender, physical activity and stress-related hormones on adolescent’s academic achievements”, International journal of environmental research and public health, 17(11), 4143.
- Aliakbari, M., Faraji, E. (2011). “Basic principles of critical pedagogy”, 2nd international conference on humanities, historical and social sciences IPEDR, 78-85.
- Anila, M. M., Dhanalakshmi, D. (2016). “Mindfulness based stress reduction for reducing anxiety, enhancing self-control and improving academic performance among adolescent students”, Indian Journal of Positive Psychology, 7(4), 390.
- Bada, S. O., Olusegun, S. (2015). “Constructivism learning theory: A paradigm for teaching and learning”, Journal of Research & Method in Education, 5(6), 66-70.
- Barlow, H. B. (1989). “Unsupervised learning”, Neural computation, 1(3), 295-311.
- Breast Cancer Prediction Using Machine Learning in Python (2023) https://wisdomml.in/breast-cancer-prediction-using-machine-learning/ (ultimo accesso giugno 2024).
- Chowdhury, A., Rosenthal, J., Waring, J., Umeton, R. (2021). “Applying self-supervised learning to medicine: review of the state of the art and medical implementations”, Informatics, 8(3), 59.
- Cunningham, P., Cord, M., Delany, S. J. (2008). “Supervised learning”, in Cord, M., Cunningham, P. (a cura di) Machine learning techniques for multimedia: case studies on organization and retrieval, Springer, Berlin-Heidelberg, 21-49.
- Das, S., Dey, A., Pal, A., Roy, N. (2015). “Applications of artificial intelligence in machine learning: review and prospect”, International Journal of Computer Applications, 115(9).
- Dontre, A. J. (2021). “The influence of technology on academic distraction: A review”, Human Behavior and Emerging Technologies, 3(3), 379-390.
- El Naqa, I., Murphy, M. J. (2015). “What is machine learning?”, in El Naqa, I., Li, R., Murphy, M. (a cura di) Machine Learning in Radiation Oncology, Springer, Cham, 3-11.
- Ertmer, P. A., Newby, T. J. (2013). “Behaviorism, cognitivism, constructivism: Comparing critical features from an instructional design perspective”, Performance improvement quarterly, 26(2), 43-71.
- Fetzer, J. H. (1990). “What is artificial intelligence?” in J.H. Fetzer (a cura di) Artificial Intelligence: Its Scope and Limits, Springer, Dordrecht, 3-27.
- Gardner, H. E. (2000). Intelligence reframed: Multiple intelligences for the 21st century, Hachette, UK.
- Gholam, A. P. (2019). “Inquiry-based learning: Student teachers’ challenges and perceptions”, Journal of Inquiry and Action in Education, 10(2), 6.
- Górriz, J. M., Ramírez, J., Ortíz, A., Martinez-Murcia, F. J., Segovia, F., Suckling, J., … Ferrandez, J. M. (2020). “Artificial intelligence within the interplay between natural and artificial computation: Advances in data science, trends and applications”, Neurocomputing, 410, 237-270.
- Hastie, T., Tibshirani, R., Friedman, J., (2009). ”Unsupervised learning” in Hastie, T., Tibshirani, R., Friedman, J. (a cura di) The elements of statistical learning: Data mining, inference, and prediction, Springer, New York, 485-585.
- Helm, J. M., Swiergosz, A. M., Haeberle, H. S., Karnuta, J. M., Schaffer, J. L., Krebs, V. E., … Ramkumar, P. N. (2020). “Machine learning and artificial intelligence: definitions, applications, and future directions”, Current reviews in musculoskeletal medicine, 13, 69-76.
- Igual, L., Seguí, S. (2024). “Supervised learning”, in Igual, L., Seguí, S. (a cura di) Introduction to Data Science: A Python Approach to Concepts, Techniques and Applications, Springer, Cham, 67-97.
- Jain, A. K., Duin, R. P. W., Mao, J. (2000). “Statistical pattern recognition: A review”, IEEE Transactions on pattern analysis and machine intelligence, 22(1), 4-37.
- Jackson, Y. (2015). The pedagogy of confidence: Inspiring high intellectual performance in urban schools, Teachers College Press.
- Kolb, D. A. (2014). Experiential learning: Experience as the source of learning and development, FT press.
- Kiselica, M. S., Baker, S. B., Thomas, R. N., Reedy, S. (1994). “Effects of stress inoculation training on anxiety, stress, and academic performance among adolescents”, Journal of Counseling Psychology, 41(3), 335.
- Lyon, G. R. (1996). “Learning disabilities”, The future of children, 6(1), 54-76.
- McLeod, J. D., Uemura, R., Rohrman, S. (2012). “Adolescent mental health, behavior problems, and academic achievement”, Journal of health and social behavior, 53(4), 482-497.
- Moldes, V. M., Biton, C. L., Gonzaga, D. J., Moneva, J. C. (2019). “Students, peer pressure and their academic performance in school”, International Journal of Scientific and Research Publications, 9(1), 300-312.
- Morimoto, J., Ponton, F. (2021). “Virtual reality in biology: could we become virtual naturalists?”, Evolution: Education and Outreach, 14(1), 7.
- Phillips, H. (2010). “Multiple intelligences: Theory and application”, Perspectives In Learning, 11(1), 4.
- Pramod, A., Naicker, H. S., Tyagi, A. K. (2021). “Machine learning and deep learning: Open issues and future research directions for the next 10 years”, in Tyagi, A. K. (a cura di), Computational analysis and deep learning for medical care: Principles, methods, and applications, 463-490.
- Rashidi, H. H., Sen, S., Palmieri, T. L., Blackmon, T., Wajda, J., Tran, N. K. (2020). “Early recognition of burn-and trauma-related acute kidney injury: a pilot comparison of machine learning techniques”, Scientific reports, 10(1), 205.
- Reiser, M., Wiebner, B., Hirsch, J., German Liver Foundation (2019). “Neural-network analysis of socio-medical data to identify predictors of undiagnosed hepatitis C virus infections in Germany (DETECT)”, Journal of Translational Medicine, 17, 1-7.
- Rodgers, K. B., Rose, H. A. (2001), “Personal, family, and school factors related to adolescent academic performance: A comparison by family structure”, Marriage & family review, 33(4), 47-61.
- Saini, S. (2021), “Supervised vs. Unsupervised Learning: What’s the Difference?”, https://www.linkedin.com (ultimo accesso giugno 2024).
- Saleem, A., Kausar, H., Deeba, F. (2021). “Social constructivism: A new paradigm in teaching and learning environment”, Perennial journal of history, 2(2), 403-421.
- Sarker, I. H. (2022). “AI-based modeling: techniques, applications and research issues towards automation, intelligent and smart systems”, SN Computer Science, 3(2), 158.
- Sgarro, G. A., Grasso, N., Lingua, A., Balestra, G. (2023a). “Monitoraggio spettrale e intelligenza artificiale come strumento di diagnostica relativo allo stato di presenza del ragnetto rosso sulle foglie di melanzana”, Bollettino della società italiana di fotogrammetria e topografia, 1, 1-10.
- Sgarro, G. A., Grilli, L., Santoro, D. (2024). “Optimal multivariate mixture: a genetic algorithm approach”, Annals of Operations Research, 1-22.
- Sgarro, G. A., Grilli, L. (2023). “Genetic Algorithm for Optimal Multivariate Mixture”, Applied Mathematical Sciences, 17(1), 15-25.
- Sgarro, G. A., Grilli, L. (2024). “Ant colony optimization for Chinese postman problem”, Neural Computing and Applications, 36(6), 2901-2920.
- Sgarro, G. A., Grilli, L., Valenzano, A. A., Moscatelli, F., Monacis, D., Toto, G., … Polito, R. (2023b). “The Role of BIA Analysis in Osteoporosis Risk Development: Hierarchical Clustering Approach”, Diagnostics, 13(13), 2292.
- Skinner, E. A., Saxton, E. A. (2019). “The development of academic coping in children and youth: A comprehensive review and critique”, Developmental Review, 53, 100870.
- Toto, G. A., Peconio, G., & Rossi, M. (2023). Nuovi percorsi di inclusione: utilizzo di un tool digitale per implementare l’educazione motoria e sportiva rivolta a studenti con autismo e disabilità cognitive. Italian Journal Of Special Education For Inclusion, 11(2), 065-072.
- Trigueros, R., Aguilar-Parra, J. M., Cangas, A. J., Bermejo, R., Ferrandiz, C., López-Liria, R. (2019). “Influence of emotional intelligence, motivation and resilience on academic performance and the adoption of healthy lifestyle habits among adolescents”, International journal of environmental research and public health, 16(16), 2810.
- Verboom, C. E., Sijtsema, J. J., Verhulst, F. C., Penninx, B. W., Ormel, J. (2014), “Longitudinal associations between depressive problems, academic performance, and social functioning in adolescent boys and girls”, Developmental psychology, 50(1), 247.
- Wang, P. (2019). “On defining artificial intelligence”, Journal of Artificial General Intelligence, 10(2), 1-37.

