Sommario
Scienza, filosofia, arte e teatro hanno proposto una variante del test di Turing al pubblico della Bright Night pisana 2023 e alla più vasta utenza della rete. Il Test è consistito in una domanda filosofica posta a una pittrice di quattro secoli fa, Artemisia Gentileschi. Due le risposte in formato testuale e interpretate in un podcast da un’attrice: una scritta da una drammaturga e una scritta dall’Intelligenza Artificiale. Sorprendenti i risultati su 750 test di ascolto e altri 500 di sola lettura, con il discorso scritto che ha ingannato più del discorso orale.
Abstract
Science, philosophy, art and theater proposed a variant of the Turing test to the public of the Bright Night 2023 in Pisa, and to the wider audience of Web users. The Test consisted of a philosophical question posed to a painter from four centuries ago, Artemisia Gentileschi. Two responses were provided in text format and interpreted in a podcast by an actress: one written by a playwright and one written by Artificial Intelligence. The results on 750 listening tests and another 500 reading tests were surprising, with written speech deceiving more than oral speech.
Keywords
Artemisia Gentileschi, Generative AI, Turing Test, AI-generated ancient Italian text.
Una domanda impossibile ad Artemisia Gentileschi
Sono state oltre 1200 le persone che hanno partecipato all’originale Test di Turing “Una domanda impossibile ad Artemisia Gentileschi”, progettato dal Dipartimento di Informatica insieme al Dipartimento di Civiltà e Forme del Sapere dell’Università di Pisa, per sondare qual è la capacità umana di riconoscere la scrittura “artificiale”. Due sono stati gli appuntamenti dal vivo, ai quali è seguito un periodo di oltre due mesi in cui il test è stato somministrato anche per via virtuale tramite un sito Web appositamente predisposto.[1] Il primo appuntamento è stato venerdì 29 settembre 2023 allo stand del Dipartimento di Informatica in Piazza dei Cavalieri (Pisa) in occasione della BRIGHT Night, la Notte europea della Ricerca; il secondo appuntamento si è svolto durante l’Internet Festival, svoltosi sempre a Pisa dal 5 all’8 ottobre 2023.
Diverse discipline: informatica, filosofia, teatro si sono coordinate per riproporre a distanza di settant’anni il test di Turing coinvolgendo docenti dell’Università di Pisa, un’attrice, una drammaturga, un regista, e un personaggio caro alla città di Pisa: Artemisia Gentileschi. Il test di Turing[2], proposto dal matematico e informatico britannico Alan Turing nel 1950, è un criterio per determinare se una macchina è in grado di manifestare un’intelligenza equiparabile a quella umana. Il test originale, denominato “il gioco dell’imitazione”, si svolge con un giudice umano che interagisce tramite una tastiera e uno schermo con due interlocutori nascosti: uno è un computer, l’altro è un essere umano. Il compito del giudice è di decidere quale dei due interlocutori sia la macchina e quale l’umano, basandosi esclusivamente sulle risposte alle domande poste.
A distanza di circa 70 anni abbiamo riproposto il test di Turing in una forma “diversa”, in cui il “gioco dell’imitazione” è svolto da un filosofo, una drammaturga, una attrice e l’IA. Il filosofo Adriano Fabris (professore di Filosofia Morale, presso l’Università di Pisa) ha posto una domanda sul legame tra arte e vita alla pittrice Artemisia, interpretata dall’attrice Pamela Villoresi[3]. La domanda è sempre la stessa ma le risposte sono diverse: una è scritta da un essere umano (la drammaturga Daniela Morelli), l’altra è scritta dall’Intelligenza Artificiale, “guidata” da Paolo Ferragina (professore di Informatica, presso la Scuola Superiore Sant’Anna e l’Università di Pisa) e Giuseppe Prencipe (professore di Informatica, presso l’Università di Pisa). Entrambe le risposte sono state interpretate dall’attrice che non conosceva la loro “natura”.
Il test è stato somministrato mediante il sito Web su menzionato, secondo due modalità: solo audio o solo testo. Nel primo caso, il pubblico ha potuto partecipare all’esperimento ascoltando un podcast contenente la domanda posta dal filosofo e le due risposte di Artemisia interpretate dall’attrice; nel secondo caso, il pubblico poteva leggere la domanda e le risposte da un testo scritto. In entrambi i casi le due risposte sono state scambiate nell’ordine man mano che il test procedeva, così da non condizionare la valutazione umana. Altro aspetto saliente è che le due modalità (solo audio o solo testo) sono state scelte per valutare quanto l’interpretazione dell’attrice potesse influenzare l’individuazione del testo “artificiale”. E come vedremo, i risultati saranno sorprendenti.
Prima di presentare e discutere i risultati del test, desideriamo commentare il perché abbiamo scelto Artemisia Gentileschi. È l’unica donna in Italia che abbia mai saputo cosa sia la pittura (Roberto Longhi); perché Pisa è la città d’origine della famiglia Lomi Gentileschi e ci poniamo sulla scia di un “Progetto Artemisia” iniziato con la famosa mostra di Palazzo Blu (Pisa, 23 marzo – 30 giugno, 2023[4]), poi approdata a Londra; e, infine, perché mettendo Artemisia a confronto con l’Intelligenza Artificiale (IA) abbiamo voluto “suggerire” l’incontro tra l’innovazione dei nostri tempi e una donna che a suo tempo fu innovatrice d’arte e di vita, ricercatrice essa stessa di un nuovo modo di rappresentare mito e realtà.
La figura 1 sottostante riporta la domanda e le due risposte ipoteticamente fornite da Artemisia (nella sua veste umana, a sinistra, e artificiale, a destra).

Il test propone un’intervista impossibile tra un filosofo dei nostri giorni e una pittrice di secoli fa. Nel formulare la domanda abbiamo fatto riferimento ad alcuni quadri di Artemisia: in Autoritratto in veste di pittura colpisce l’espressione di Artemisia persino pacificata, concentrata nel lavoro, rispetto alla sconvolgente potenza di altri dipinti come Giuditta che decapita Oloferne. Certe ferite non le nasconde il pennello, ed è per questo che la domanda prova a sollecitare una risposta che rimanda al rapporto tra arte e vita.
La struttura della risposta “umana” è teatrale e propone un personaggio che entra in relazione con l’interlocutore con lieve diffidenza rispetto all’indagine più profonda che l’intervistatore sollecita. Il linguaggio e le tematiche prendono spunto dalle risposte di Artemisia al processo voluto dal padre, Oratio Lomi Gentileschi, contro Agostino Tasso, stupratore della giovane figlia. Processo “subìto” da Artemisia che, seppur vittima, fu torturata per verificare l’attendibilità dell’accusa. La scrittura della risposta attinge, inoltre, alle lettere che più tardi la pittrice stessa inviava ai suoi committenti e, naturalmente, all’idea che la drammaturga si è fatta di lei.
Per quanto riguarda invece la risposta “artificiale” si è proceduto come segue. Abbiamo adottato come IA Generativa il tool ChatGPT nella sua versione 3.5 (settembre 2023), progettando ed eseguendo prompt ad hoc. In particolare, la risposta “artificiale” è stata ottenuta tramite una sequenza di interazioni con ChatGPT, del tipo domanda-risposta (riportate qui di seguito), in cui si è dapprima generato il testo in lingua italiana corrente, e poi si è chiesto di trasformarlo in un italiano che ricalcasse la lingua dell’epoca:
[Prompt] C’è davvero un rapporto tra arte e vita, o invece l’arte è qualcosa di autonomo, e proprio perciò l’arte può offrire salvezza ai dolori della vita?
[Prompt] E secondo te, Artemisia Gentileschi come l’avrebbe interpretata questa domanda?
[Prompt] Puoi immaginare di produrre circa 1500 caratteri in cui provi a spiegare la risposta di Artemisia alla domanda?
[Prompt] Puoi darmi la risposta come se parlasse Artemisia Gentileschi, usando un linguaggio tipico del 1500 in Italia?
Quest’ultima domanda è stata sottoposta a ChatGPT più volte, fornendo come input la risposta alla penultima domanda, per ovviare alla limitatezza del contesto adottato da ChatGPT 3.5.
L’intervento registico ha attraversato le fasi che dal testo scritto hanno portato al podcast audio. Per non influenzare Pamela Villoresi nella sua interpretazione, non le si è fornita alcuna informazione sull’origine dei due testi. La regia si è occupata pertanto di un inquadramento interpretativo del personaggio Artemisia, non della caratterizzazione dell’una o dell’altra risposta. La registrazione è stata ripetuta il numero necessario di volte per un risultato ottimale dal punto di vista di qualità tecnica dell’audio (tre registrazioni: una prova registrata, una registrazione buona, una registrazione di sicurezza) e non con lo scopo di una particolare ricerca interpretativa.
Il questionario e alcune risposte “interessanti”
Dopo aver ascoltato o letto le due risposte di Artemisia, ciascun partecipante ha risposto a una serie di domande poste mediante un form digitale, quali le seguenti:
- Quale delle due risposte che hai precedentemente ascoltato, secondo te, è stata scritta dall’essere umano? [due possibili risposte tra cui selezionare]
- Con quale grado di sicurezza hai risposto? [valori da 1, basso, a 5, alto]
- Se vuoi, condividi con noi la motivazione della tua scelta tra la risposta A e la risposta B (per esempio, indicando tre aggettivi per la tua scelta). [risposta a campo libero]
- Qual è la tua fascia di età? [5 possibili fasce preimpostate]
- Qual è il tuo titolo di studio? [4 possibili risposte preimpostate]
Le risposte alle domande 1, 2, 4 e 5 saranno oggetto di analisi nelle pagine seguenti. Per quanto riguarda la domanda 3 abbiamo analizzato nel dettaglio le risposte fornite dai partecipanti che hanno sbagliato nell’individuare il testo scritto dall’essere umano. Ne riportiamo alcune che riteniamo particolarmente interessanti, così da identificare degli elementi che hanno indotto alla scelta errata, specificando tra parentesi a quale tipo fanno correttamente riferimento, se umana o artificiale:
La prima risposta [ndr. umana] utilizza conoscenze sul linguaggio dell’epoca e sicuramente testimonianze sul carattere della pittrice ma è più vaga sul rapporto tra arte e vita. La seconda [ndr. artificiale] mi sembra più arbitraria e dunque immagino sia stata pensata dall’ umano.
Troppo descrittiva come risposta, meno sentimentale [ndr. umana].
Attraverso questa risposta si entra in un contatto più intimo con i pensieri dell’artista [ndr artificiale].
Originale, inconsueta, personale [ndr. artificiale].
Meno ironica, più immediata [ndr. artificiale].
Di seguito riportiamo alcune risposte alla domanda 3, da parte di partecipanti che hanno, invece, individuato correttamente il testo “umano”:
Forma linguistica più dialogica [ndr. in quella artificiale].
La prima [ndr. umana] personalizzata, dettagliata, minuziosa. La seconda [ndr. artificiale] impersonale, filosofica.
[ndr. umana] contiene un pezzo di informazione non stimolato dalla domanda, come ad esempio le considerazioni sulla bottega e l’urgenza della consegna.
Prima risposta [ndr. artificiale] era troppo formale con le parole che non avevo sentito quasi mai e non mi dava nessuna emozione. Seconda risposta [ndr. umana] dall’inizio mi dava i brividi e mi tirava a sentire più volte. Così dalla mia esperienza seconda risposta era quella del umano perché lo capivo come aveva creato il testo e che emozioni aveva messo lì.
Durante lo svolgimento della BRIGHT Night, la drammaturga e il regista hanno effettuato alcune interviste audio e video dal vivo chiedendo ad alcuni partecipanti le loro impressioni su quanto avevano ascoltato. Riportiamo la verbalizzazione di alcuni commenti che riteniamo particolarmente significativi, specificando come fatto sopra la tipologia di risposta – umana o artificiale – alla quale si fa riferimento:
“Esperimento molto bello, suggestivo, bellissimo, due audio… molto sentiti, molto profondo, non è stato semplice distinguere, è difficile comprendere la differenza, io ho messo come umana la seconda [ndr. artificiale], risposta dolorosa, profonda e sentita.”
“Difficile capire… Ho studiato IA, tempo fa, era più facile riconoscerla… Ho pensato che la risposta umana è la seconda [ndr. artificiale]. La prima era più disordinata… Chat Gpt? Non la uso spesso, preferisco fare le cose io invece che usare IA”
“L’abbiamo ascoltata insieme, abbiamo cercato se ci fossero trucchi, AI vuole iniziare un dialogo più coinvolgente?”
“Umana per me è la prima [ndr. umana] perché è puntata a mettere la pulce nell’orecchio dell’ascoltatore ed è meno lineare rispetto alla seconda. La prima risposta è più divagata e la divagazione è una caratteristica dell’essere umano”
“… Pensare che una di queste due risposte possa essere data dall’IA è sconvolgente – molto difficile scegliere, mi ha fatto dubitare la tipologia di vocaboli, ma direi che la prima risposta è umana [ndr. umana]. Tre aggettivi? Risposta profonda, umana e reale”
“La risposta umana è la prima [ndr. umana], è più empatica: vieni con me in negozio, ti faccio vedere, gli dice… Chat Gpt non ci arriva… per fortuna! Sorprendente, incredibile!”
“Me lo aspettavo più semplice, mi ha sorpreso sentire una risposta dell’IA scritta in questo modo, ho scelto quella che mi sembrava più pensata da un umano: la prima [ndr. umana]. L’attrice era molto più dentro la recitazione, non sono riuscito a differenziare bene le risposte… Implicazioni che ne possono derivare: utilizzare l’IA per falsificare video – audio… avrei timore… se l’IA potesse scrivere il discorso di fine anno del Presidente della Repubblica, sarebbe comico e preoccupante – dobbiamo iniziare a preoccuparci?”
In generale, nelle interviste dal vivo i partecipanti hanno espresso apprezzamento e interesse verso il test svolto, sorpresa e indecisione nelle risposte. Il tema che emerge è anche come viene percepita l’IA, quale utilizzo può farne il comune consumatore e con quali conseguenze. Si derivano così sensazioni che vanno dalla fascinazione, alla diffidenza, all’inquietudine. Inoltre, abbiamo spesso notato un moto di sorpresa spiegato dal fatto che i fruitori dell’esperimento non si aspettavano che distinguere le fonti autoriali sarebbe stato così difficile, proprio perché entrambi i testi risultavano convincenti. In questo elemento si individua un altro contributo dell’interpretazione attoriale: avendo restituito entrambe le risposte in modo convincente, l’attenzione degli ascoltatori si è dovuta attivare oltre le loro stesse aspettative e quindi il test è stato affrontato con una concentrazione intensa, tanto da ascoltarlo più volte.
Alcuni numeri sui partecipanti
Le tabelle 1 e 2 sottostanti riportano alcuni numeri relativi alla partecipazione al test, segmentati per età, grado di istruzione, ed erogazione del test (solo audio o solo testo). A seguire anche due grafici a torta (Figura 2) che offrono un colpo d’occhio ancora più immediato su questi numeri.
| Età | Totale Audio | Totale Testo | Totale |
| meno di 18 anni | 43 | 30 | 73 |
| 18 – 30 anni | 279 | 131 | 410 |
| 31 – 40 anni | 85 | 98 | 183 |
| 41 – 50 anni | 96 | 101 | 197 |
| oltre 50 anni | 254 | 141 | 395 |
| TOTALE | 758 | 501 | 1259 |
| Grado di istruzione | Totale Audio | Totale Testo | Totale |
| diploma di scuola superiore | 204 | 91 | 295 |
| laurea (triennale, magistrale o ciclo unico) | 359 | 249 | 608 |
| master, dottorato, … | 133 | 124 | 257 |
| altro | 49 | 29 | 78 |
| TOTALE | 758 | 501 | 1259 |
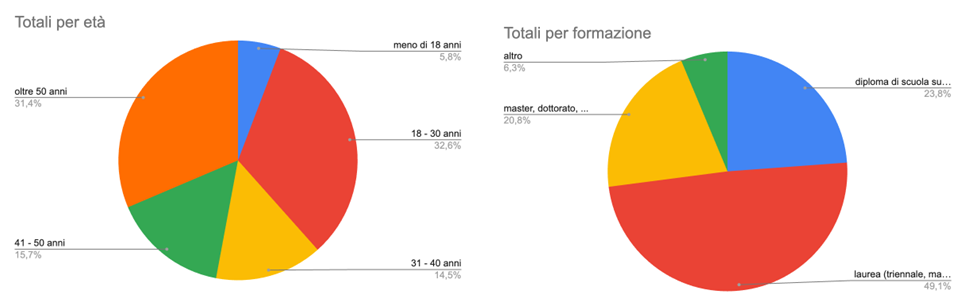
Come già accennato, l’esperimento ha coinvolto oltre 1200 persone. La fascia d’età più numerosa è stata quella degli studenti/laureati tra i 18 e i 30 anni, seguita dalle persone sopra i 50 anni in possesso di laurea. Interessante è anche la presenza di persone con titoli post-laurea, quali dottorato o master.
I risultati del test (domande 1, 2, 4 e 5)
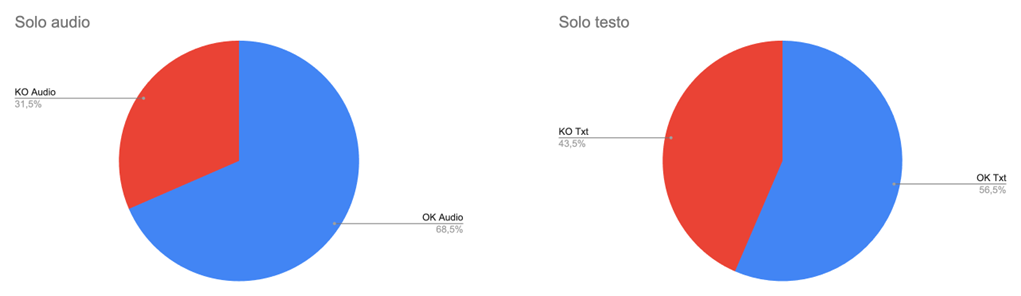
I grafici a torta riportati nella Figura 3 sottostante ci offrono dei risultati sorprendenti, anche alla luce della tipologia di domanda e di testi da valutare. Risulta che la percentuale di coloro che sbagliano nell’individuare il testo “umano” è particolarmente alta: 31.5% nel caso di ascolto (solo audio), e 43.5% nel caso di lettura (solo testo). Appare quindi evidente che la lettura “inganni” più facilmente dell’ascolto, sottolineando quanto sia elevata la capacità dei sistemi IA attuali di generare un testo linguisticamente ben formato, anche nel contesto difficile di un italiano d’altri tempi. Riteniamo anche che l’intonazione data dall’attrice, per quanto non a conoscenza dell’autore del testo, possa aver influenzato la valutazione evidenziando le espressioni “umane” più di quelle “artificiali”, e guidando quindi gli ascoltatori più facilmente nell’individuazione del testo “umano”. Oppure, si è trattato di una maggiore attenzione posta nell’ascolto rispetto alla lettura, come notato nelle interviste dal vivo durante la BRIGHT Night. In ogni caso, ci saremmo aspettati il contrario, visto che la lettura consente di rivedere più facilmente le frasi e quindi quegli aspetti che possono meglio guidare nell’identificazione del testo umano.
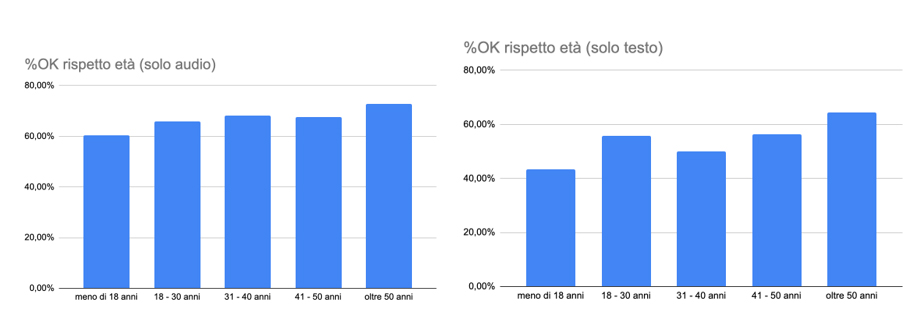
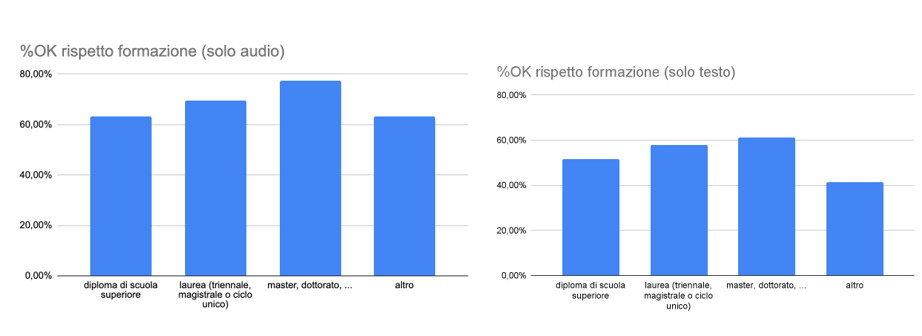
I grafici illustrati nelle seguenti Figure dettagliano il risultato per età (Figura 4) e grado di istruzione (Figura 5), sempre suddivisi per tipologia di erogazione: solo audio (sinistra) o solo testo (destra). Si nota che, nel caso di solo audio (a sinistra), la percentuale di risposte corrette aumenta sia con l’età che con il grado di istruzione. Stessa cosa dicasi nel caso di solo testo (a destra), seppure si apprezzi una leggera flessione per la fascia d’età 31-40 anni. Inoltre, il gap in percentuale nelle risposte corrette tra i giovanissimi e coloro che hanno più di 50 anni aumenta nel caso del solo testo, arrivando a circa 20 punti percentuali. Di contro la differenza è maggiore nel caso del grado di istruzione se consideriamo l’audio.
Conclusioni
Alla fine di questa esperienza ci preme sottolineare alcuni aspetti che riteniamo salienti e che, comunque, confermano quelli ottenuti da altri esperimenti recenti svolti a livello internazionale[1] pur su una tipologia di testi alquanto diversi e sicuramente, nel nostro caso, crediamo, più difficili per l’IA. Innanzitutto, colpisce l’alto numero di persone che sono state ingannate dal testo “artificiale”. Ciò significa due cose: sia che le prestazioni dell’IA generativa sono elevate e in grado, appunto, di ingannare, sia che gli esseri umani sono forse propensi più che in passato a farsi ingannare, cioè sono abituati a riconoscere come umano un discorso sviluppato da un algoritmo. La seconda cosa che ci preme sottolineare riguarda il fatto che il discorso scritto ha ingannato più del discorso orale. Anche qui l’interpretazione può essere duplice. Da una parte va segnalato il fatto che ciò può dipendere da una possibile intonazione differenziata da parte dell’attrice Pamela Villoresi, che può aver indirizzato gli ascoltatori, pur non conoscendo lei la “natura” delle risposte. Dall’altra parte, la causa può essere legata al fatto che siamo ormai meno abituati a leggere e a comprendere le implicazioni della lettura di quanto non facciamo per un contesto verbale. Ciò è confermato anche dalle analisi relative al grado d’istruzione, anche se, l’IA riesce comunque a trarre in inganno con percentuali significative anche coloro che hanno svolto un dottorato o un master.
Tutto ciò può suggerire una riflessione più generale sul cambiamento di mentalità attualmente in corso. In un contesto di interazioni immediate, come quelle verbali, la propensione a confondere le espressioni umane e gli output artificiali sta aumentando. La commistione è certamente favorita dall’aumento delle prestazioni dell’IA generativa. Ma certamente questo esito è legato, ripetiamo, anche alla nostra disposizione a dare credito a tali prestazioni.
In generale, riteniamo sorprendente che circa una persona su tre coinvolta nel test sia stata ingannata, e questo indipendentemente dal fatto che il test sia stato somministrato in forma scritta o audio. Sicuramente le IA del futuro saranno ancora più accurate e simil-umane, ma già questi numeri fanno riflettere.

