Sommario
Large Language Models (LLM) sono il risultato di tre importanti progressi scientifici in soli 10 anni del Deep Learning applicato al linguaggio naturale. Illustreremo questi progressi, tra cui la soluzione allo storico dilemma sul significato delle parole. I LLM sono alla base di sistemi di Generative AI come ChatGPT, e dimostrano una sorprendente efficacia in molti compiti compresi compiti creativi come la generazione di immagini, codice o musica da descrizioni testuali. Sembrano persino esibire abilità emergenti che vanno oltre i compiti per cui sono stati allenati. I loro rapidi progressi hanno sollevato preoccupazioni su eventuali rischi di un loro utilizzo indiscriminato. Rifletteremo sulle loro potenzialità e sulle paure che sollevano, confrontando atteggiamenti apocalittici e ottimistici. Di sicuro va evitato il rischio che la tecnologia resti appannaggio di poche aziende con le risorse tecniche ed economiche per svilupparla.
Abstract
Large Language Models (LLMs) are the result of three major scientific breakthroughs in just 10 years of Deep Learning, applied to natural language. We will illustrate these advances, including the solution to the historic dilemma over the meaning of words. LLMs are the basis of Generative AI systems such as ChatGPT, and demonstrate surprising effectiveness in many tasks including creative tasks such as generating images, code or music from text descriptions. They even seem to exhibit emerging abilities in tasks besides those they were trained for. Their rapid progress has raised concerns about the possible risks of their indiscriminate use. We will reflect on their potential and the fears they raise, comparing apocalyptic and optimistic attitudes. Certainly, the risk must be avoided that this technology remains the prerogative of a few companies with the technical and economic resources to develop it.
Keywords
Large Language Models, Deep Learning, ChatGPT, Artificial Intelligence
1. Introduzione
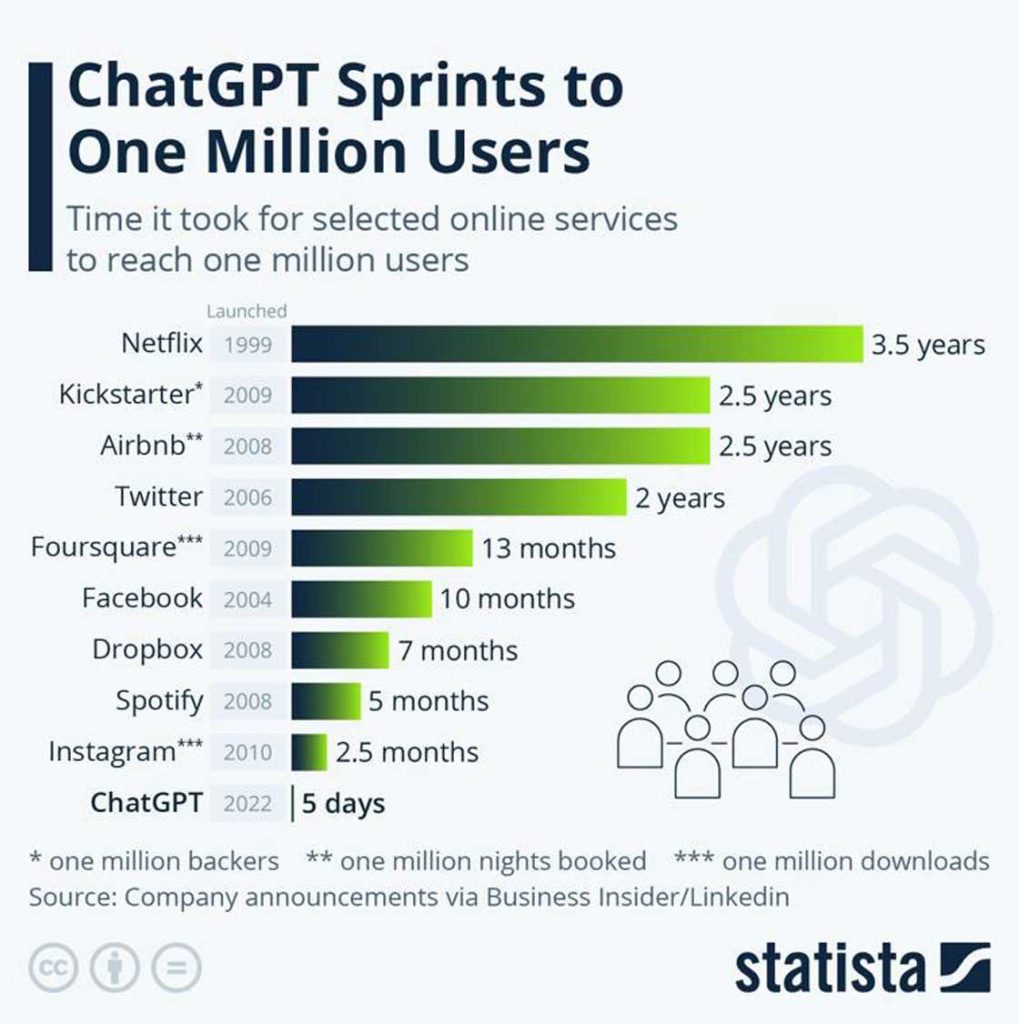
Come mai ChatGPT si è diffuso così rapidamente da raggiungere 100 milioni di utenti in circa due mesi? Eppure, fino a poco tempo fa, le chatbot erano considerate servizi molto rudimentali, incapaci di fornire risposte adeguate e di sostenere dialoghi coerenti con le persone. Finora, la tecnologia principale per costruirli era basata su schemi di dialogo preconfezionati (template), con domande tipiche per ciascuno scopo (intent) con corrispondenti risposte
(fulfillment) che i sistemi si limitavano ad adattare, inserendovi porzioni di frasi relative al tema in questione.
ChatGPT supera i limiti delle chatbot tradizionali combinando tre tecniche: un Large Language Model (GPT-3.5) di cui sfrutta la capacità di capire e generare frasi in linguaggio naturale; la messa a punto (fine-tuning) sul compito specifico di rispondere a domande; e il Reinforcement Learning per imparare a scegliere la mossa migliore di una strategia, in questo caso la risposta migliore, per raggiungere l’obiettivo, ossia di compiacere l’interlocutore.
I Large Language Model (LLM) sono modelli di reti neurali profonde (Deep Learning) in grado di acquisire una vasta conoscenza di una lingua, ricavandola da enormi quantità di testi, tratti principalmente dal Web. Essi imparano dai testi a svolgere un compito apparentemente semplice: a predire la prossima parola a conclusione di una frase. Per esempio, la pagina di Wikipedia sull’Italia riporta: “La capitale è Roma”, quella sulla Francia dice: “La capitale è Parigi”, ecc. Si intuisce che un LLM sappia completare la frase “La capitale è _” con la parola “Parigi”, a fronte della domanda “Qual è la capitale della Francia?”: il fine-tuning
gli ha insegnato la forma della risposta e l’attention, di cui parleremo dopo, a tenere conto della parola “Francia” dal contesto della domanda.
Ma le capacità dei LLM si sono presto dimostrate ben superiori alla loro intrinseca capacità di completare una frase o di comporre intere storie a partire da un breve spunto iniziale.
Il Reinforcement Learning utilizza un premio da assegnare al sistema quando la mossa che sceglie è utile a raggiungere l’obiettivo. Nel caso di ChatGPT l’obiettivo è di soddisfare le richieste dell’interlocutore, e il premio si basa sul confronto tra più risposte possibili. OpenAI, l’azienda che produce Chat-GPT, ha raccolto tantissime risposte alternative, ricavate da dialoghi con ‘allenatori’ umani che interagivano con la chatbot da allenare e davano un punteggio alle migliori. Il LLM di base (GPT-3.5) è stato messo a punto (fine-tuned) in modo da generare la risposta migliore coerentemente rispetto a questi esempi di risposte. OpenAI offre dettagli sul processo di sviluppo e sul ruolo dei revisori, secondo le consuete pratiche dell’azienda, in un blog1.
ChatGPT è diventato popolare perché OpenAI ha messo a disposizione un demo online per dialogare con la chatbot nella propria lingua, anziché doverlo programmare come gli altri LLM. Milioni di persone lo hanno voluto mettere alla prova e i commenti si sono divisi tra gli entusiasti e i detrattori. I primi erano stupiti e orgogliosi di vedere una piccola creatura alzarsi in piedi e compiere i primi passi, considerandolo un momento cruciale del suo sviluppo. Gli altri si sono sforzati di farla cadere con uno sgambetto o di farla cadere dalla bicicletta, che non aveva mai provato. Cercare domande sbagliate a cui ChatGPT dà risposte sbagliate è diventato uno sport diffuso, anziché cercare le domande giuste a cui questo strumento può dare la risposta giusta. Per farsi un’opinione scientificamente valida, non bastano singoli esempi scelti appositamente, ma occorre innanzitutto capire la tecnologia e i suoi limiti per saperla sfruttare al meglio. Anche coi motori di ricerca, ci siamo rapidamente adattati ai loro limiti: sapendo che si basano sul confronto tra parole chiave della ricerca e parole presenti nei testi, abbiamo imparato a scegliere le parole giuste e a cambiarle quando non ottenevamo i risultati che ci aspettavamo.
ChatGPT è solo uno dei tanti modi di usare i LLM. La ricerca sta facendo rapidissimi progressi in questo settore e nuovi modelli vengono sviluppati in continuazione. Non dobbiamo quindi pensare che ChatGPT sia il meglio che la tecnologia possa offrire, ma solo un passo di uno sviluppo che continuerà a stupirci. Vediamo quindi quali sono i costituenti di queste nuove tecnologie, le loro qualità (il Bello), i loro limiti (il Brutto) e i potenziali rischi (il Cattivo).
2. I Large Language Model
I LLM costituiscono il secondo dei tre inaspettati breakthrough scientifici del Deep Learning applicato al Natural Language Processing, avvenuti nel breve periodo di dieci anni.
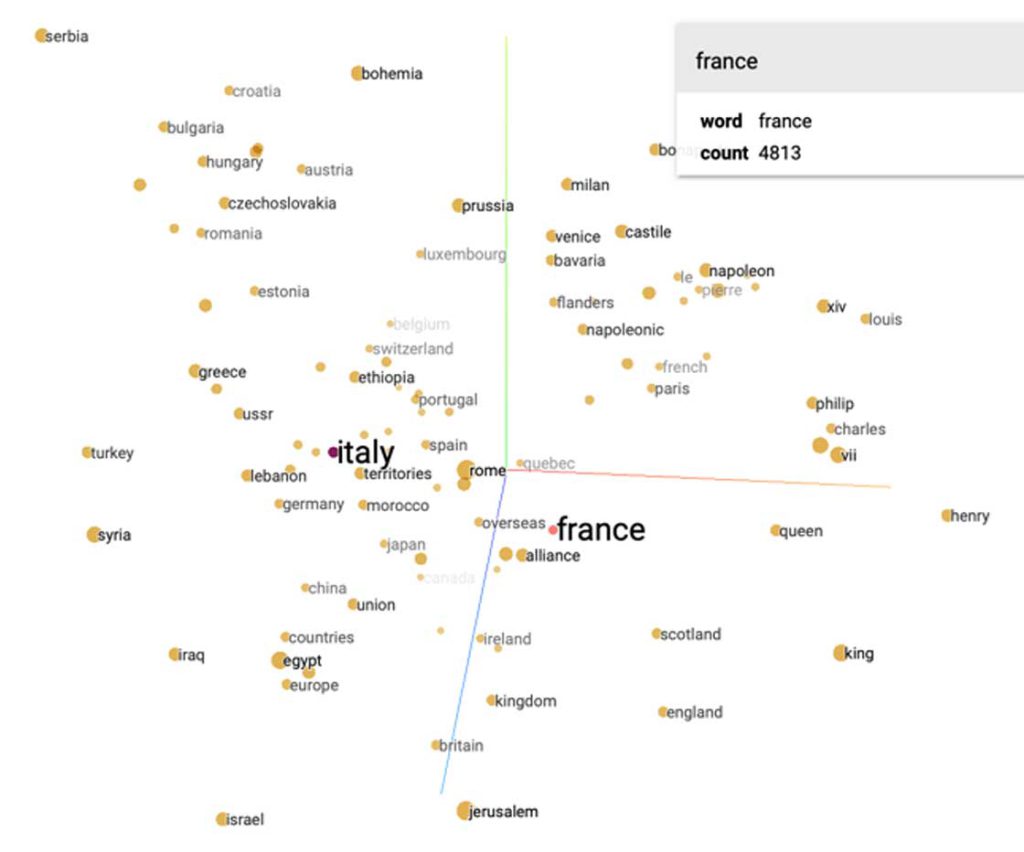
Il primo breakthrough fu l’invenzione di un metodo per rappresentare il senso delle parole (Collobert, et al., 2011) con tecniche di apprendimento non supervisionato (self-supervised): ossia bastava fornire a una rete neurale un elevato numero di frasi, perché imparasse a cogliere somiglianze di significato tra le parole che le componevano. Ogni parola viene rappresentata da un word-embedding, un vettore di centinaia di numeri, ciascuno che in qualche modo coglie una particolare sfumatura di significato. Parole con significato simile si trovano vicine tra loro in questo spazio, ad esempio Francia, Italia e Germania sono vicine2, facendo supporre che possano essere accomunate da qualcosa che noi chiameremmo la categoria nazione, Microsoft, Google e Apple saranno altrettanto vicine, legate forse dal concetto di azienda digitale. Categorie e concetti emergono naturalmente, come parole presenti in un certo intorno dello spazio degli embedding, anche più articolati e numerosi dei concetti che si possono ritrovare in dizionari o ontologie curate a mano. Vi sono però termini ambigui, come ‘apple’, il cui significato dipende dal contesto.
Su questo interviene il secondo breakthrough, con l’introduzione di un meccanismo di attenzione, descritto nell’articolo seminale “Attention is All You Need” (Vasvani, et al., 2017). Con l’attention si riescono a cogliere legami e relazioni tra le parole in un contesto e costruire i cosiddetti Transformer, ossia modelli che trasformano una sequenza di input in una sequenza di output, conservando le relazioni tra le parole. Più in generale, si tratta di reti neurali utilizzate per elaborare sequenze di dati (quindi frasi, voce, fenomeni con andamenti temporali, ecc.) che vengono però elaborati in parallelo, non sequenzialmente, per sfruttare l’accelerazione delle GPU, e che utilizzano l’attention, per tener conto della rilevanza reciproca tra gli elementi della sequenza: per esempio nella traduzione automatica, il testo originale viene trasformato nella sua traduzione in un’altra lingua, tenendo conto del senso e della corrispondenza con le parole nell’originale.
La tecnica dei Transformer applicata alla traduzione automatica è stata uno dei più clamorosi successi del Deep Learning, che ha portato a surclassare in pochi mesi per qualità ed efficienza i precedenti sistemi di traduzione automatica che avevano richiesto anni di sviluppo e messa a punto.
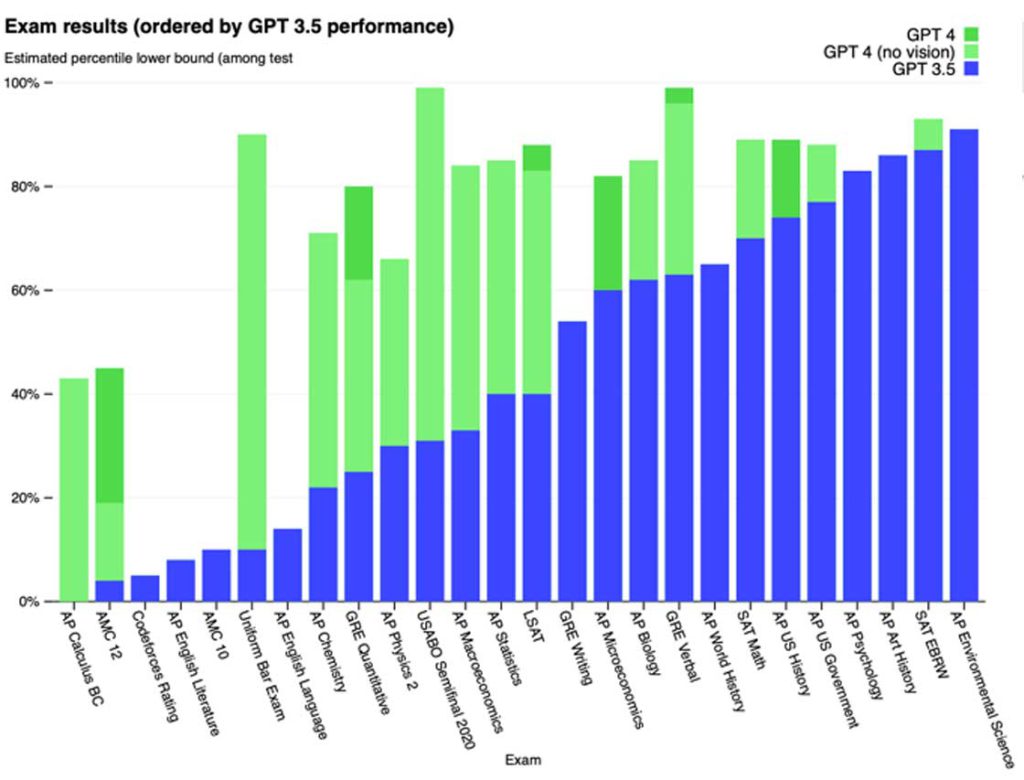
I Transformer hanno poi sbaragliato tutte le altre tecniche usate in precedenza nel campo del NLP in ogni altro compito: traduzione, classificazione, riassunto, risposte a domande, analisi di opinioni, inferenza linguistica, ecc. Basta scorrere la classifica dei sistemi a confronto su SuperGlue3, una raccolta di benchmark di analisi linguistica, per notare non solo che i migliori fanno tutti uso di Transformer, ma che molti già superano in accuratezza le capacità umane
GPT-4, il successore di GPT-3.5, è stato in grado di superare diversi testi di accesso scolastici e universitari
I Transformer possono essere adattati a nuovi compiti in modo relativamente semplice con la tecnica del fine-tuning. Si parte da un modello pre-allenato su un’ampia raccolta di testi e gli si fornisce una raccolta relativamente piccola di esempi del nuovo compito da svolgere: il modello si adatta rapidamente a svolgerlo. È un progresso notevole perché accelera lo sviluppo di nuove potenti applicazioni, sfruttando l’enorme conoscenza linguistica contenuta in un unico Transformer generico, e specializzandolo verso un nuovo compito.
3. Il Bello
I Transformer fanno parte della Generative AI, sistemi di Intelligenza Artificiale capaci di generare risposte in modo creativo, producendo risultati che sorprendono per la loro qualità che sembrerebbe tipica della mente umana: testi, immagini, musica e video possono venire generati a partire da frasi che le descrivono. Ad esempio, un testo può essere tradotto a partire dall’originale in un’altra lingua; una figura ottenuta da una descrizione della sua composizione; una musica dal testo di una canzone.
La tecnologia dei Transformer è applicabile a modalità diverse, dalla voce ai testi, dalle immagini ai video. Per questo in futuro verranno sempre più sviluppati modelli multimodali, in grado di interagire accettando input sensoriali di tipi diversi e producendo loro combinazioni, rendendo sempre più naturale l’interazione con loro.
I LLM mostrano risultati impressionanti per una serie di attività di elaborazione di testi come la risposta alle domande (QA), la generazione di codice (o altri linguaggi formali/assistenza editoriale) e la generazione di storie (fittizie).
Dai primi modelli nel 2018 ne sono apparse decine di varianti, da quelle per testo a quelli per immagini, da quelli monolingue a quelli multilingue, da quelli monomodali a quelli multimodali (testo e immagini) come GPT-4.

I LLM esibiscono capacità che sorprendono gli stessi ricercatori, al punto che sono diventati oggetti di studio per capire quali siano le loro capacità: un settore di studio chiamato BERTology. Tale studio si esegue stimolando i modelli con delle sonde (probe), per verificare se sanno svolgere compiti che richiedono capacità per le quali non sono stati allenati.
I LLM sembrano mostrare capacità emergenti (Wei & al., 2022), ossia che appaiono solo quando si accresce notevolmente la loro dimensione, in termini sia di dati di apprendimento che di numero di parametri di cui si compongono; capacità che non manifestano i modelli di analoga architettura ma di dimensioni più piccole. Ad esempio, modelli di dimensioni elevate cominciano a esibire capacità di ragionamento di tipo Chain of Thought, come nella figura accanto, in cui il modello risolve un problema che richiede un ragionamento matematico, seguendo la traccia indicata nella prima domanda/risposta sulle palle da tennis. Questa sorprendente potenzialità dà ulteriore stimolo a una corsa verso la costruzione di modelli sempre più grandi.
4. Il BRUTTO
I LLM costruiscono risposte a partire dalle conoscenze linguistiche che hanno accumulato nei loro parametri, non estraggono la risposta da fonti esterne. Perciò sono utilizzabili per compiti in cui questo modo di operare sia efficace, quali:
– Traduzione automatica
– Riassunto di un testo
– Sintesi di una raccolta di testi
– Comporre bozze (di articoli, mail, ecc.)
– Trasformare sequenze di un tipo in un altro (testo in immagine, voce in
testo, ecc.)
Per questi compiti possono essere di valido aiuto, mentre, se si cerca di usarli per ottenere informazioni su fatti di cui hanno avuto poco sentore, possono cadere in allucinazioni (hallucinations), introducendo nella risposta elementi plausibili ma non proprio corretti.
Questo problema può essere affrontato con tecniche che guidano un modello a produrre frasi che contengono informazioni precise e corrette ricavate da fonti sicure, ad esempio con la tecnica del prompting, adottata nei sistemi di data-to-text44 .
ChatGPT è stato allenato a non prendere posizioni su argomenti controversi, e se la cava relativamente bene se interrogato su questioni su cui esiste un’opinione prevalente. Ad esempio, se gli si chiede se i vaccini possono causare autismo, risponde che la scienza è unanime nel negare una correlazione e riporta che gli studi che ne sostenevano l’esistenza sono stati smentiti.
Questo è stato confermato da esperimenti5 su vari benchmark, dove ChatGPT risponde correttamente a domande triviali, su fatti che ricorrono frequentemente su Internet. Invece la comprensione del testo necessaria per rispondere a una domanda complessa, magari costituite da un singolo esempio di testo, è ancora insufficiente.
D’altra parte, questo significa che ChatGPT è influenzato dalle opinioni prevalenti o più diffuse, e quindi non va usato per farsi opinioni o suffragare opinioni preconcette. Occorre sempre esercitare il proprio spirito critico e considerare le sue risposte per quello che sono, una estrapolazione dai testi su cui il sistema è stato allenato. Su molti argomenti non esiste una verità univoca e non si può certo pensare di trovarla tramite ChatGPT. Una delle stesse fonti principali su cui ChatGPT è allenato è Wikipedia: ma le informazioni riportate su certi temi nella stessa Wikipedia sono il risultato di litigi tra i curatori che cercano di imporre il proprio punto di vista.
Magari in futuro verranno prodotti chatbot che incarnano modi di pensare diversi, come avviene per le testate giornalistiche, e gli utenti potranno scegliere a quale di questi aderire per formarsi le proprie opinioni. Questo però richiederebbe che la capacità di costruire LLM diventasse più accessibile, come diremo più avanti.
I LLM non hanno inoltre capacità astratte quali quella di conteggiare, di fare calcoli, di effettuare ragionamenti logici o di pianificare in più passi. Ad esempio,
non sempre sanno calcolare quanto è lunga una parola o disegnare un’immagine con esattamente 5 dita delle mani o una bocca sorridente con il numero giusto di denti.
Alcuni studi hanno verificato che gli attuali LLM da una parte esibiscono davvero competenze linguistiche formali (come la conoscenza lessicale e grammaticale,
illustrate nella figura 6), ma dall’altra sono privi di competenze funzionali (richieste per svolgere calcoli matematici o ragionamento logico) (Mahowald, et al., 2023).
Ciò non dovrebbe stupire perché essi non sono stati allenati per eseguire ragionamenti astratti, ma solo per prevedere la prossima parola.
ChatGPT per esempio è stato allenato a gestire dialoghi, e quindi a tenere traccia dell’intera conversazione, rispondendo a tono, a volte scusandosi gentilmente se gli si segnala un errore e fornendo una nuova risposta per correggersi.
Questo fa sembrare che ChatGPT impari attraverso i dialoghi: in realtà ciò di cui tiene conto è limitato alla conversazione in corso, ma alla prossima avrà dimenticato tutto. OpenAI sollecita gli utilizzatori a inviare loro feedback sulle risposte, al fine di migliorare il modello, ma ciò avviene con l’aggiunta di nuovi esempi alla raccolta usata per il passo di Reinforcement Learning, che richiede settimane o mesi di allenamento e viene fatto quindi solo di tanto in tanto.

ChatGPT ha sollevato perplessità su possibili effetti che il suo utilizzo potrebbe avere sulla scuola, con studenti che si fanno produrre risposte o saggi da ChatGPT esimendosi dallo studio; sul mondo dell’informazione, sostituendo i giornalisti nella stesura di notizie. Altri sistemi come DALL-E 26 potrebbero avere impatti nel mondo creativo, sostituendo gli illustratori con strumenti che generano automaticamente immagini o produrre musica e video. Di recente è stata minacciata una causa contro7 l’azienda che produce StableDiffusion8, sostenendo che utilizza immagini di apprendimento ottenute in violazione del copyright.
Più grande è il LLM, più difficile diventa, sia per gli esseri umani che per tecniche algoritmiche, distinguere le notizie scritte da una macchina dagli articoli scritti da esseri umani. Su come comportarsi di fronte a tali situazioni le opinioni sono divergenti, se bandirne l’uso o controllarlo ad esempio con tecniche di watermarking.
5. Il CATTIVO
È ben noto che le applicazioni di AI generativa come le chatbot a volte possono essere difficili da controllare e si può finire in conversazioni in cui vomitano commenti razzisti o sessisti. OpenAI ha affrontato questo problema identificando contenuti tossici o semplicemente su temi politici controversi e cercando di intercettarli a priori.
Di fatto oggi gli unici che possono permettersi le enormi risorse di calcolo necessarie per allenare un LLM sono le grandi aziende tecnologiche. E il loro ulteriore sviluppo e diffusione richiede investimenti massicci, come dimostrano i $20 miliardi che Microsoft ha annunciato di voler investire in OpenAI e nell’integrazione di ChatGPT con il suo motore di ricerca Bing. In questo settore stiamo per assistere a una guerra tra titani, per conquistare spazi in un nuovo settore applicativo: Microsoft con il sistema Prometheus9 contro Google con Bard10. Il passo da una chatbot a un sistema integrato di dialogo e ricerca è tutt’altro che banale, come emerge dai primi passi falsi di entrambi i sistemi, e richiederà una riprogettazione sostanziale dell’architettura del sistema integrato.
Sarà una battaglia cruciale con effetti dirompenti anche sull’ecosistema digitale del web: infatti finora i motori di ricerca guadagnavano sulla pubblicità che attraevano sfruttando l’interesse per i contenuti che altri introducevano nei loro siti web. Questi ultimi venivano a loro volta remunerati con un aumento di traffico e una quota di entrate pubblicitarie. Ma con i chatbot che producono direttamente le risposte senza fare riferimento alle fonti, si spezza questo cordone ombelicale
che alimenta i produttori di contenuti. Gli effetti di questo cambiamento di paradigma sono del tutto imprevedibili.
Ci sono due strade possibili per rendere accessibile e democratizzare la tecnologia dei LLM: progetti dal basso che aggregano una comunità di ricercatori nello sviluppo di modelli Open-Access, come BLOOM (Le Scao & al., 2022), o costruire e rendere disponibili ai ricercatori infrastrutture pubbliche dotate di risorse di calcolo adeguate, come chiedono a gran voce i ricercatori stessi sia in USA11 che in Europa12.
6. LE PAURE
Come ogni nuova tecnologia di largo impiego, anche i LLM suscitano reazioni contrastanti, dalle paure apocalittiche all’ottimismo sfrenato.
Persino i tre ricercatori, considerati i padri del Deep Learning, hanno preso posizione, in una specie di tentativo di rimettere il genio nella bottiglia.
Yoshua Bengio ha sottoscritto una lettera aperta del Future of Life Institute (FOLI), in cui si chiede una moratoria di sei mesi nello sviluppo di ulteriori più potenti LLM, finché non vengano definite nuove norme sul loro utilizzo, anche se è scettico che la lettera abbia alcun effetto e consideri inadatte le norme di regolamentazione attualmente proposte.
Geoff Hinton ha invece interrotto la sua collaborazione con Google, a cui ha venduto dieci anni fa la sua startup DNNresearch, oltre che per ragioni di età, anche per poter essere libero di esprimersi sui rischi dell’AI. Ha ribadito che Google si è finora comportato in modo responsabile nell’utilizzo dell’AI e continua a credere nell’importanza degli studi in materia. Finora, come molti altri, riteneva che la possibilità di costruire sistemi più intelligenti delle persone fosse lontano di 30 o 50 anni, mentre ora si è ricreduto.
I rischi che intravede sono nella diffusione su larga scala di fake-news, nell’eliminazione di posti di lavoro e infine nell’utilizzo per lo sviluppo di armi letali autonome.
Invece Yann LeCun non ha firmato la lettera del FoLI, sostenendo che la tecnologia è tuttora in evoluzione e come tutte le nuove tecnologie, forme di controllo e di sicurezza dovranno venire introdotte man mano che si sviluppa.
Le questioni segnalate da Hinton sono state ampiamente discusse negli anni scorsi e pericoli simili sono stati attribuiti anche ad altre tecnologie introdotte in passato. Ricordo, ad esempio, con quanta sufficienza e preoccupazione i media trattavano la nascente tecnologia di Internet una trentina di anni fa. Le preoccupazioni di oggi riguardano quindi più in generale l’uso responsabile delle tecnologie. Viene da chiedersi dunque cosa ci sia di particolare nei LLM che sta facendo concentrare l’attenzione di governi e istituzioni sulla loro regolamentazione.
Le fake news sono sempre esistite ed il problema principale è riconoscerle e bloccarne la diffusione, non tanto impedire che vengano prodotte. Lo spazio pubblico è già saturo di frodi ed è difficile immaginare come l’AI possa renderlo molto peggiore. Il numero che conta non è quello di quante ne vengano prodotte, ma di quante raggiungono l’obiettivo di una diffusione virale, che non è facilmente prevedibile, tanto meno se queste vengono prodotte in automatico un tanto al kilo. Il timore delle deep fake (foto fittizie ad alto realismo) ignora il fatto che PhotoShop è in uso da decenni con lo stesso obiettivo, e gli stessi media tradizionali ne fanno abbondante uso.
Hinton afferma di essere rimasto spiazzato dalle capacità raggiunte dai LLM in poco tempo. In effetti la sua ricerca è stata latente per trenta anni ed è esplosa negli ultimi dieci. Ma lo sviluppo esponenziale delle tecnologie informatiche non è una novità: ne avvengono ogni 15 anni ed hanno effetti dirompenti e sostanzialmente positivi per tutti. Perché l’AI dovrebbe essere diversa e più pericolosa di altre? Perché l’AI produce sistemi più capaci degli umani? Ma in molti compiti i computer sono già ampiamente superiori agli umani. Perché l’AI potrebbe riprodurre se stessa? Ma i compilatori non sono altro che programmi che scrivono programmi. Perché l’AI potrebbe ritorcersi contro gli umani? Ma questi sono scenari da fantascienza, nessun sistema potrebbe diventare autonomo se qualcuno non gli attribuisce questa capacità: i LLM al massimo possono dire sciocchezze ma non possono fare male fisico. Stranamente le norme proposte di regolamentazione dell’AI, come l’European AI Act, escludono invece dal loro ambito di applicazione i sistemi di utilizzo militare. Non è ridicolo che non si vogliano contrastare proprio le applicazioni più pericolose?
Alcuni criticano i LLM sostenendo che non sono in grado di capire. Ma l’informatico Yoav Shahom, in un recente seminario su “Understanding understanding13” afferma che tali critiche sono troppo vaghe, fintanto che non si definisce cosa significhi “capire”. Finora, l’unico criterio pratico per stabilire se qualcuno, studente o computer, capisce, è di porgli delle domande su un tema di cui sappiamo le risposte. Ma su tutti i test di “comprensione” i LLM superano ormai abbondantemente il livello umano. Del resto, anche Richard Feynman diceva che “nessuno può dire di capire la fisica quantistica”; eppure le sue equazioni funzionano. Quindi ciò che conta è se l’AI funziona, non se capisce.
D’altro lato i LLM esibiscono capacità emergenti, ossia che appaiono solo quando raggiungono grandi dimensioni e che i modelli più piccoli non hanno. È un fenomeno simile a quello che il Nobel Giorgio Parisi analizza nei sistemi complessi, il cui funzionamento è determinato dalla combinazione su larga scala di semplici leggi probabilistiche, come quello dei LLM di saper predire la prossina parola. La mente umana ha difficoltà a spiegare i fenomeni complessi perché siamo abituati a scomporre i fenomeni in piccole parti legate da relazioni di causa-effetto.
Ciò che stupisce è che si esprimano in maniera melodrammatica con affermazioni facilmente confutabili, anche esperti della materia come Gary Marcus e Noam Chomsky14. Soprattutto è insensato che a partire da un singolo esempio di errore nella risposta di un LLM, si arrivi a conclusioni generalizzate su quanto mai si possa realizzare tramite il Machine Learning.
I tentativi attuali di regolamentazione come lo European AI Act sono goffi e complicati: un testo di 107 pagine, che anziché limitarsi a stabilire dei principi o dei diritti, si avventura nell’impostare un farraginoso processo di certificazione per garantire gli utenti contro i potenziali danni dei sistemi di IA. Ma siccome non si può effettuare tecnicamente la certificazione dei sistemi o degli sviluppatori, si limita a introdurre norme e verifiche sul processo di sviluppo di tali applicazioni. La certificazione dovrebbe essere svolta attraverso informazioni che le aziende stesse forniscono, visto che si vuole garantire la segretezza della proprietà industriale dei prodotti. Il processo di certificazione è estremamente laborioso e si stima costi intorno ai 300 mila €, senza contare che dovrebbe essere replicato in ogni paese dell’Unione, e ciascun paese dovrebbe dotarsi di un apposito ente di certificazione, dotato di “risorse adeguate”. La direttiva stessa riconosce questo problema di costi e per non penalizzare le piccole aziende, propone di introdurre delle “regulatory sandboxes”, un misterioso sistema per provare in un ambiente controllato il funzionamento delle applicazioni, da realizzare in ciascun paese. Ma le radici stesse della normativa sono in dubbio, in quanto definisce il settore dell’AI non in termini di ciò di cui si occupa o di cosa faccia, ma delle tecniche che usa, come dire che l’oftalmologia viene definite dall’uso delle lenti e non come lo studio della visione.
Infine, l’European AI Act15 esclude esplicitamente dal suo campo di intervento le applicazioni militari, che sono quelle che davvero producono morte e danni, mentre un LLM non può causare danni, al massimo può dire qualche sciocchezza.
Un’altra paura è quella della perdita di posti di lavoro, che Goldman Sachs stima in 300 milioni di posti di lavoro solo in USA e in Europa. Altri all’opposto sostengono che altrettanti posti verranno rimpiazzati da nuovi lavori, relativi a nuovi prodotti o servizi basati su AI, come è successo con l’introduzione di altre tecnologie in passato. Francamente non saprei fare delle stime, ma sono convinto che l’AI avrà un impatto significativo sul mondo del lavoro, in quanto si tratterà di una General Purpose Technology, che cambierà il modo di svolgere moltissime attività umane. Inoltre, i cambiamenti del digitale sono molto più rapidi di quelli delle tecnologie del passato; quindi, non ci sarà tempo sufficiente perché i lavoratori si riqualifichino per le nuove attività. Ciò a cui si assiste già adesso è una divaricazione, tra lavori super-specializzati e ben remunerati, ma poco numerosi e un alto numero di lavori di scarso livello e poco pagati, al servizio delle macchine, della cosiddetta Gig-economy16. Questo produrrà un enorme divario
tra lavoratori e un corrispondente divario di potere economico e finanziario nelle mani delle poche grandi aziende digitali che controllano le piattaforme e i servizi digitali. Questi due divari saranno la causa di possibili disuguaglianze sociali su cui bisognerà intervenire per tempo.
Tranne la questione delle disuguaglianze e dell’impatto sul lavoro, ritengo che le altre paure siano ingiustificate e siano relative a fenomeni che già esistevano prima dell’irruzione sulla scena dei LLM.
Si tratta di questioni che riguardano l’impatto economico e sociale dell’utilizzo di nuove tecnologie, di cui sono responsabili sia le aziende che gli utenti. Ad esempio le fake-news esistevano prima dei social media, e a diffonderle attraverso i social media sono gli utenti stessi, con la complicità dei media che guadagnano sulla pubblicità che cresce con l’interesse che esse suscitano.
Gli informatici si devono sentire in dovere di segnalare alla società l’importanza e il ruolo che le nuove tecnologie possono avere e di chiedere di investire nella ricerca per sviluppare e migliorare tali tecnologie. Ma il più delle volte gli scienziati non sono in grado di prevedere gli effetti delle innovazioni, come diceva Rodney Brooks17, nel 2017, mentre oggi si esagera al contrario. Nessuno sapeva predire quali sarebbero stati gli effetti delle precedenti General Purpose Technologies, sviluppate dall’informatica: nel 1980 il personal computer e nel 1995 Internet. Eppure, alcuni ne avevano segnalato gli effetti dirompenti18. Ma se analizziamo le preoccupazioni e le ipotesi di regolamentazione che venivano proposte all’epoca, ci rendiamo conto di quanto fossero fuori obiettivo. Esse avrebbero bloccato i benefici e non risolto il problema più serio della concentrazione di potere tecnologico a cui assistiamo oggi. In altre parole, bisogna padroneggiare la tecnologia, fare in modo che sia disponibile a tutti e non concentrata in poche mani, e seguirne le evoluzioni per adattare la società ai cambiamenti che essa comporta.
7. CONCLUSIONI
ChatGPT ha portato all’attenzione del vasto pubblico la tecnologia dei LLM, che sono alla sua base, come di tante altre possibili applicazioni. La sua capacità di interagire e di rispondere in linguaggio naturale in più lingue ha fatto insorgere curiosità e lasciare intendere che esibisca capacità paragonabili all’intelligenza umana. Tramite esperimenti scientifici controllati, è stato possibile verificare che questo può succedere, ma solo in compiti di trattamento di testi molto specifici, mentre i LLM sono ben lontani dalle capacità della cosiddetta Artificial General Intelligence (AGI).
Ma i progressi rapidi della tecnologia fanno immaginare ulteriori miglioramenti, sia incrementali, sia dovuti ad ulteriori eventuali breakthrough, visto il sempre maggior interesse che queste tecnologie stanno suscitando nei ricercatori e negli investitori. Limitarsi quindi alle critiche per gli attuali limiti della tecnologia non
tiene conto che ChatGPT non sarà l’ultimo dei modelli e se si guardasse alla velocità dei progressi recenti, potremmo presto stupirci per nuovi risultati in arrivo.
Occorre però evitare che il controllo della tecnologia rimanga appannaggio di poche grandi imprese che possono permettersi le enormi risorse necessarie per costruire i modelli più sofisticati e che questo consenta loro di aumentare il loro dominio sull’economia digitale.
In un caso o nell’altro, l’evoluzione tecnologica dei modelli di AI porterà a cambiamenti dirompenti nel modo di sviluppare applicazioni, nella concentrazione di potere tecnologico e nella disparità tra i detentori della tecnologia e gli altri, e infine nel mondo delle professioni.
BIBLIOGRAFIA
Collobert, R., J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, & P. Kuksa. (2011).
Natural Language Processing (Almost) from Scratch. JMLR. Tratto da https://www.jmlr.org/papers/volume12/collobert11a/collobert11a.pdf
Vasvani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., . . .
Polosukhin, I.
(2017). Attention is all you need. Neurips 2017. Curran.
Mahowald, K., Ivanova, A. A., Blank, I. A., Kanwisher, N., Tenenbaum, J. B., &
Fedorenko, E. (2023, January 23). Dissociating language and thought in large language models: a cognitive perspective. Tratto da ArXiv: https://arxiv.org/abs/2301.06627
Le Scao, T., & al., e. (2022). BLOOM: A 176B-Parameter Open-Access
Multilingual Language Model. Tratto da ArXiv: https://arxiv.org/pdf/2211.05100
Wei, J., & al., e. (2022, 12). Emergent Abilities of Large Language Models. Tratto
da ArXiv: https://arxiv.org/pdf/2206.07682
https://openai.com/blog/how-should-ai-systems-behave/ ↩︎
https://projector.tensorflow.org (provare inserendo France nella Search) ↩︎
https://super.gluebenchmark.com/leaderboard ↩︎
https://www.amazon.science/blog/automatically-generating-text-from-structured-data ↩︎
https://www.geeksforgeeks.org/open-ai-gpt-3/ ↩︎
https://openai.com/dall-e-2/ ↩︎
https://www.theverge.com/2023/1/17/23558516/ai-art-copyright-stable-diffusion-getty-images-lawsuit ↩︎
https://stability.ai/blog/stable-diffusion-public-release ↩︎
https://blogs.microsoft.com/blog/2023/02/07/reinventing-search-with-a-new-ai-powered-microsoft-bing-and-edge-your-copilot-for-the-web/ ↩︎
https://blog.google/technology/ai/bard-google-ai-search-updates/ ↩︎
https://www.ai.gov/wp-content/uploads/2023/01/NAIRR-TF-Final-Report-2023.pdf ↩︎
https://claire-ai.org/vision/ ↩︎
https://claire-ai.org/vision/ ↩︎
https://www.nytimes.com/2023/03/08/opinion/noam-chomsky-chatgpt-ai.html ↩︎
https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=celex%3A52021PC0206 ↩︎
https://en.wikipedia.org/wiki/Gig_economy ↩︎
https://rodneybrooks.com/the-seven-deadly-sins-of-predicting-the-future-of-ai/ ↩︎
http://www.interlex.it/attualit/letterap.htm ↩︎
Giuseppe Attardi è stato professore ordinario di Informatica presso l’Università di Pisa. Ha anche lavorato presso l’AI Lab del MIT, il Sony Paris Research Laboratory, l’ICSI a Berkeley e lo Yahoo Research Barcelona. Ha sviluppato Omega, una logica descrittiva; CMM, il Garbage Collector utilizzato in Java e DeSR, un parser multilingue con reti neurali. Ha partecipato allo sviluppo di Arianna, il primo motore di ricerca italiano e ha introdotto la tecnica della categorizzazione per contesto delle pagine web. È fondatore o socio di alcune startup, in Italia e in Spagna. Ha contribuito alla realizzazione delle reti in fibra ottica dell’Università di Pisa e del GARR e a promuovere l’accesso a Internet in Italia. Ha guidato lo sviluppo della piattaforma cloud GARR. Ha contribuito alla stesura della strategia italiana sull’Intelligenza Artificiale e alla nascita del primo Dottorato di Ricerca nazionale in Intelligenza Artificiale.Email: attardi@gmail.come Design. Fondatore e presidente del centro METID (1996-2011), della SIe-L (2003-2007), del consorzio Poliedra (2002-2017), delegato del Rettore per l’e-learning e l’innovazione didattica. È stato tra i primi in Italia a sperimentare la didattica a distanza; nel 2000 ha coordinato il primo corso di laurea interamente online. Ha pubblicato oltre 250 lavori, diretto o collaborato a numerosi progetti nazionali ed europei, svolgendo ricerche nei seguenti settori: analisi a molti criteri, sistemi di aiuto alla decisione, modelli per la valutazione d’impatto ambientale, metodi di ottimizzazione, smart city e smart mobility, simulazione e serious games, formazione multimediale.Attualmente è presidente del Comitato UNICEF di Milano.

